
In the pharmaceutical and clinical diagnostics industries, machine learning is transforming product development by accelerating innovation, reducing costs, and enhancing accuracy throughout the entire research-to-delivery process.
This post explores three real-world applications of machine learning in the pharmaceutical industry:
- QSAR modeling to predict the physicochemical properties of compounds in early development.
- Process optimization to forecast yields and improve efficiency in real time.
- Biomarker discovery to enhance diagnostic accuracy and inform the design of more personalized clinical trials.
Each application is illustrated with a case study built on real datasets and implemented with Neural Designer, showcasing how machine learning can tackle complex biomedical challenges.
QSAR Modeling
QSAR (Quantitative Structure-Activity Relationship) is a methodology that enables the prediction of a chemical compound’s biological or toxicological activity based on its molecular structure.
This technique is based on the premise that molecules with similar structures will have similar effects in biological systems.
How does it work?
- Molecular descriptors are calculated (e.g., molecular weight, polarity, number of bonds, specific substructures).
- Machine learning models are designed to associate these descriptors with a target property, such as toxicity, affinity, or solubility.
- The model can then be used to predict the behavior of new compounds without requiring direct experimentation.
Relevance for the Pharmaceutical Industry
In the drug development process, QSAR modeling is helpful for:
- Identifying promising candidates from large chemical libraries.
- Reducing animal experimentation, especially in toxicity testing.
- Accelerating development in preclinical phases, lowering costs.
- Increasing safety by anticipating adverse reactions.
For companies specializing in plasma-derived therapies and clinical diagnostics, these models allow for rapid and accurate evaluation of:
- The toxicity of new excipients or adjuvants.
- Molecular interactions with plasma proteins.
- The environmental impact of residual compounds.
Case Study: Oral Toxicity Prediction
A representative example of a QSAR application is the prediction of the acute oral toxicity of chemical compounds.
Dataset Used
- Name: QSAR Oral Toxicity Dataset
- Source: UCI Repository
- Data: 8,982 compounds, 1,024 binary molecular descriptors generated with PaDEL-Descriptor.
- Target variable: Binary classification: toxic (1) or non-toxic (0).
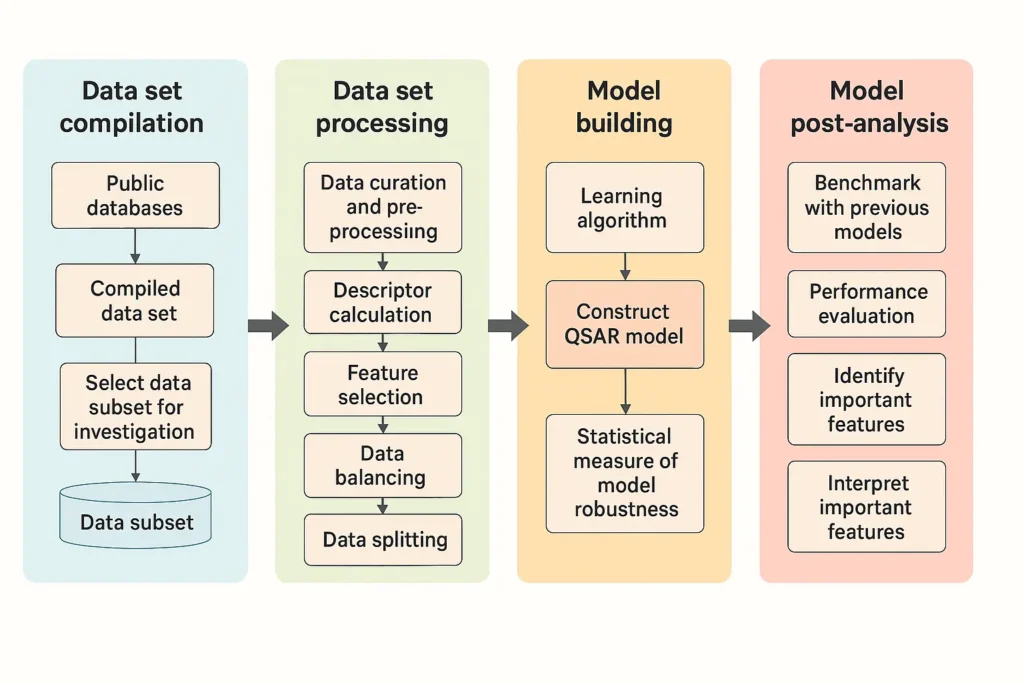
Workflow with Neural Designer
- CSV data import.
- Input/output definition.
- Training, validation, and testing.
- Interpretation: variable importance ranking, sensitivity, and confusion matrix.

Results
- Approximately 85% accuracy.
- Detection of toxic structural patterns (e.g., aromatic groups, halogens, amines).
- Explainability: Which molecular descriptors most influence toxicity?

Impact and Benefits
- Reduced costs and time in selecting safe compounds.
- Support for regulatory decisions, including justification to agencies like EMA or FDA.
- Compliance with ethical principles in experimentation.
- Improved molecular design, eliminating patterns associated with toxicity.
Conclusion
QSAR modeling, enhanced by tools like Neural Designer, represents an effective solution for addressing toxicity and chemical safety challenges in the pharmaceutical industry.
This approach can be integrated as part of an innovation pipeline, driving informed R&D decisions, ensuring quality, and minimizing risks from early development stages.
Process optimization
What is data-driven process optimization?
In the biopharmaceutical industry, the production of biomolecules such as antibodies, therapeutic proteins, or vaccines takes place in highly controlled bioreactors. These systems continuously collect data from sensors such as:
- Temperature
- pH
- Dissolved oxygen
- Stirring speed
- Nutrient concentrations
The use of machine learning allows the construction of models that predict key process outcomes (such as product yield) based on this data.
These models can be utilized to enhance real-time decision-making and optimize production processes.
Relevance of machine learning in the pharmaceutical industry
Companies that manufacture plasma-derived products, therapeutic proteins, and even diagnostic components, benefit from these models to:
- Increase production efficiency by predicting yield before the batch is completed.
- Anticipate quality failures or unwanted conditions.
- Dynamically adjust operational conditions more accurately than with fixed rules.
Case Study: Predicting Yield with Production Data
Dataset used
- Name: Biopharmaceutical Manufacturing
- Source: Kaggle
- Observations: Data from sensors in real industrial processes (~3,000 samples)
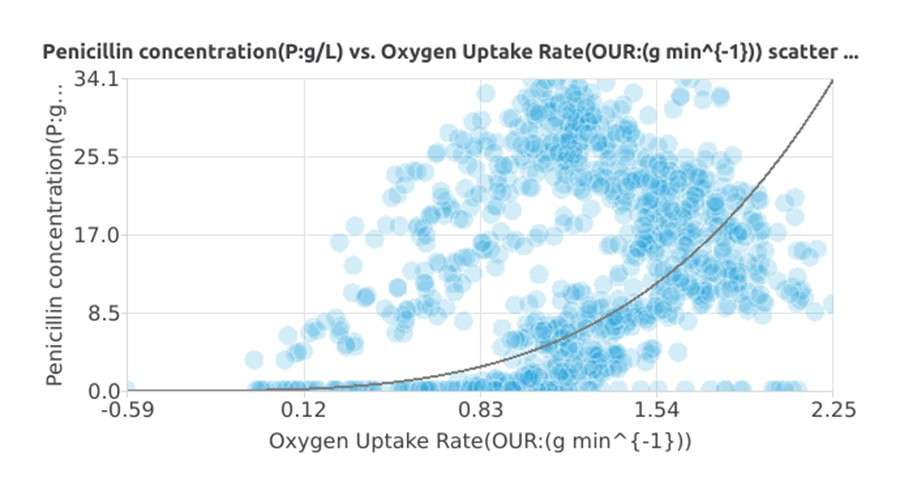
- Variables: 33 variables such as pH, temperature, oxygen, fed volume, cell density, etc.
- Target Variable: Product Concentration (mg/L) — final product concentration in the batch
Workflow with Neural Designer
- Import data in CSV format
- Define inputs (process variables) and output (concentration)
- Train, evaluate, and validate the model
- Perform sensitivity analysis to identify the most influential variables
Impact and Benefits
- Process optimization: Maximizes yield without the need for trial and error
- Cost reduction: Prevents batch repetitions or waste
- Proactive prevention: Identifies conditions that lead to low yield
- Improved quality control: Strengthens data-based online decisions
Conclusion
Machine learning applied to process data modeling represents a strategic tool for companies. It allows anticipation of outcomes, optimization of conditions, and data-driven decision-making.
Thanks to platforms like Neural Designer, this type of analysis can be easily implemented within current biopharmaceutical production environments, integrating data science with process engineering.
Biomarker discovery
Introduction
The discovery of biomarkers using machine learning techniques allows for the identification of measurable biological variables that help to:
- Diagnose diseases.
- Classify patients based on their clinical status.
- Predict responses to treatments or the progression of diseases.
These techniques are especially useful when working with high-dimensional data, such as proteomic or metabolomic profiles, where the number of variables exceeds the number of samples.
Relevance
In the context of developing diagnostic solutions, this approach allows for:
- Designing new assays for early disease detection.
- Optimizing panels of serological or molecular tests.
- Automating the classification of samples with a high volume of variables.
- Supporting the validation of clinically relevant biomarkers using real-world data.
These tools can be integrated with automated diagnostic platforms and adapted for use in various areas, such as immunology, hematology, or infectious diseases.
Practical Case: Patient Classification Using Molecular Profiles
Dataset:
- Name: Serum Proteomic Patterns for Disease Classification
- Source: UCI Machine Learning Repository
- Description: A dataset of serum protein expression obtained through mass spectrometry. Each sample corresponds to a patient classified as either negative or positive for pancreatic cancer.
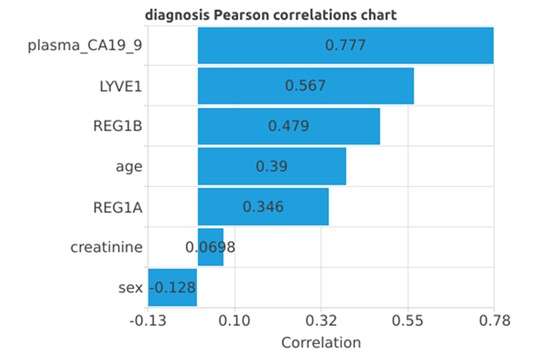
Structure
Over 20,000 variables per patient, each corresponding to the intensity of a spectrometric peak.
The objective is to train a classification model to distinguish between the three groups while also identifying the most relevant signals.
Application with Neural Designer
- Binary classification (positive or negative for cancer).
- Selection of predictive variables → candidate biomarkers.
- Interpretation through analysis of variable importance and sensitivity.
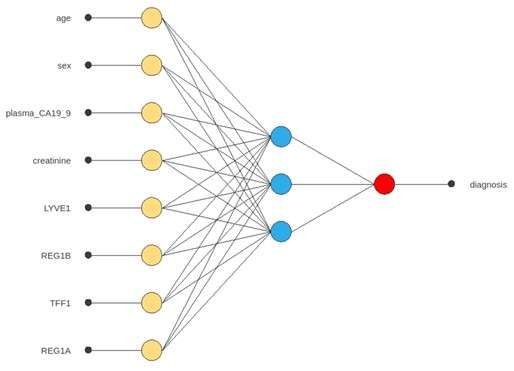
In this case, the signals analyzed correspond to serum proteins, i.e., blood-derived biomarkers.
The same approach could be applied to similar datasets with molecular markers in urine, such as those used for renal diagnosis, urinary infections, or bladder cancer detection.
Conclusion
In the machine learning pharmaceutical industry, the discovery of biomarkers through machine learning is a powerful tool for accelerating the development of diagnostic products and advancing toward more precise, segmented, and automated medicine.
These models can be incorporated into:
- Expand the catalog of reagents and assays.
- Computationally validate new clinical hypotheses.
- Strengthen the automation of complex data analysis.


