Contents
Performance benchmarking
As we know, the volume, variety, and velocity of information stored in organizations are increasing significantly.
Therefore, for machine learning tools to be efficient, they must process large amounts of data in the shortest time possible.
Key performance indicators typically measured here are data capacity, training speed, inference speed, and model precision.

DATA CAPACITY

TRAINING SPEED

MODEL PRECISION

INFERENCE SPEED
Benchmarking measures performance using a specific indicator, resulting in a metric that is then compared to others.
This enables organizations to develop plans for implementing improvements or adapting specific best practices, typically to enhance a particular aspect of performance.
In this way, they learn how well the targets perform and, more importantly, the business processes that explain why these firms are successful.
Data capacity tests
Nowadays, common datasets used in machine learning might contain thousands of variables and millions of samples.
However, when building models with big datasets, machine learning platforms may crash due to memory problems.
Therefore, tools capable of processing these volumes of data are necessary.
The data capacity of a machine learning platform can be defined as the biggest dataset that it can process. In this way, the tool should perform all the essential tasks with that dataset.
We can measure data capacity as the number of samples a machine learning platform can process for a given number of variables.
This metric depends on numerous factors:
- The programming language in which it is written (C++, Java, Python…).
- The strategies used within the code for the efficient use of memory.
- The optimization algorithms it contains (SGD, Adam, LM…).
To compare the data capacity of machine learning platforms, we follow the next steps:
- Select a reference computer (e.g., CPU, GPU, RAM).
- Choose a reference benchmark (data set, neural network, training strategy).
- Choose a reference model (number of layers, number of neurons…).
- Choose a reference training strategy (loss index, optimization algorithm…).
- Choose a stopping criterion (loss goal, epochs number, maximum time…).
Note that selecting a dataset suite is necessary.
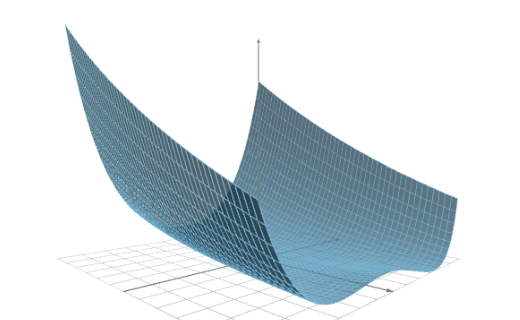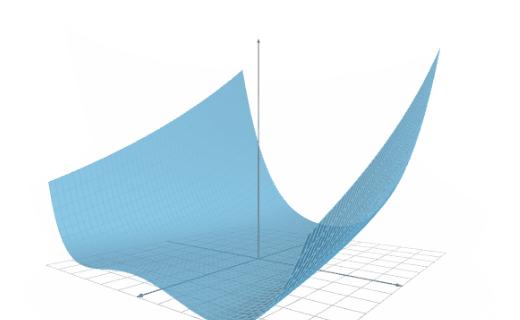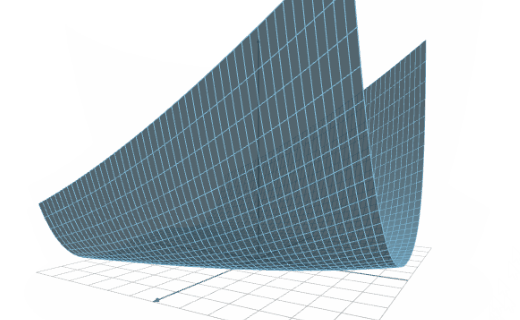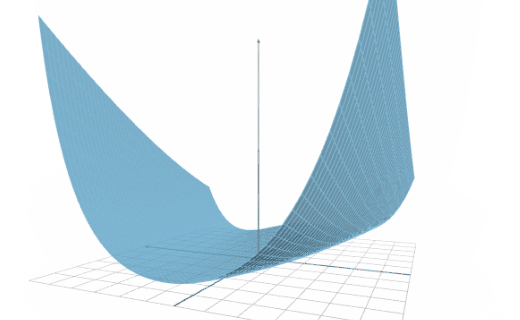
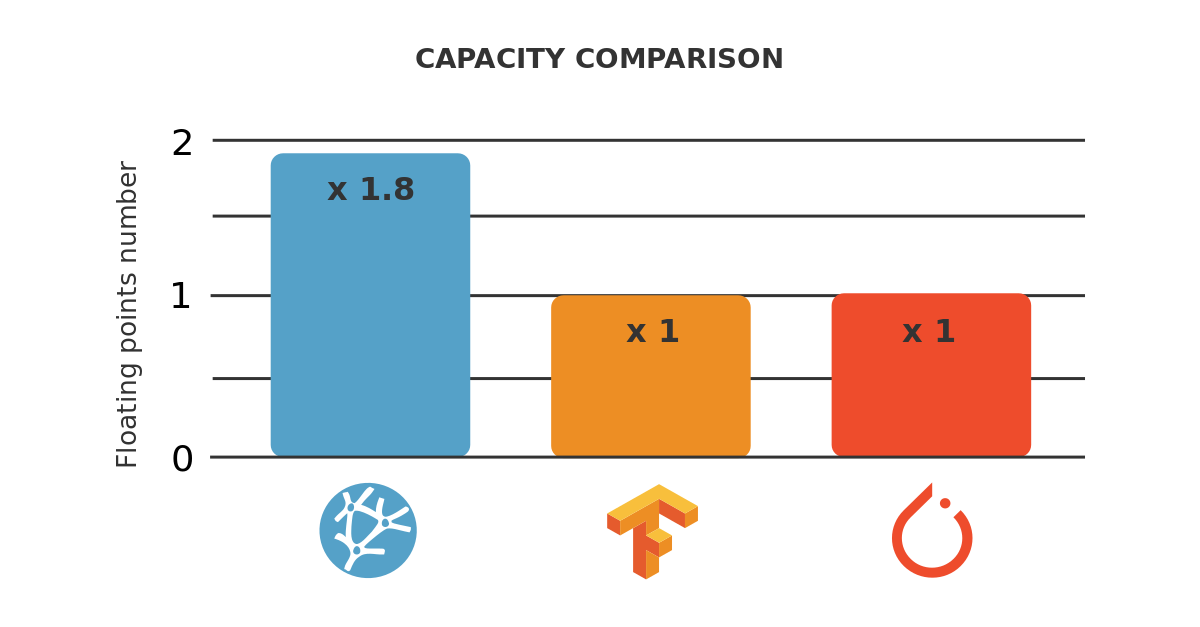
The following figure illustrates the result of a data capacity test with two platforms.
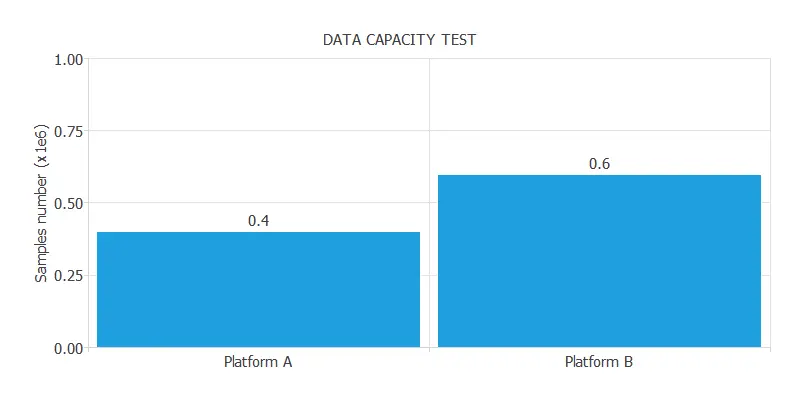
As we can see, Platform A can analyze up to 400,000 samples, while Platform B can analyze up to 600,000 samples.
Therefore, we can say that the capacity of Platform B is 1.5 times the capacity of Platform A.
As a practical example, consider that our computer has 16 GB of RAM and our dataset has 500,000 samples. Platform A would throw a memory allocation error, while Platform B would train the model.
Training speed tests
One of the most critical factors in machine learning platforms is the time they need to train the models.
Indeed, modeling big data sets is very expensive in computational terms.
Training machine learning models with big datasets can take several hours.
Moreover, before deploying a model, it is usually necessary to train many candidate models to select the best-performing one.
This can make it impractical to use some platforms for some applications.
The training speed of a machine learning platform depends on numerous factors:
- The programming language in which it is written (C++, Java, Python…).
- The high-performance computing (HPC) techniques that it implements (CPU parallelization, GPU acceleration…).
- The optimization algorithms it contains (SGD, Adam, LM…).
Training speed is usually measured as the number of samples per second that the platform processes during training.
To compare the training speed of machine learning platforms, we follow the next steps:
- Choose a reference benchmark (data set, neural network, training strategy…).
- Select a reference computer (e.g., CPU, GPU, RAM).
- Compare the training speed.
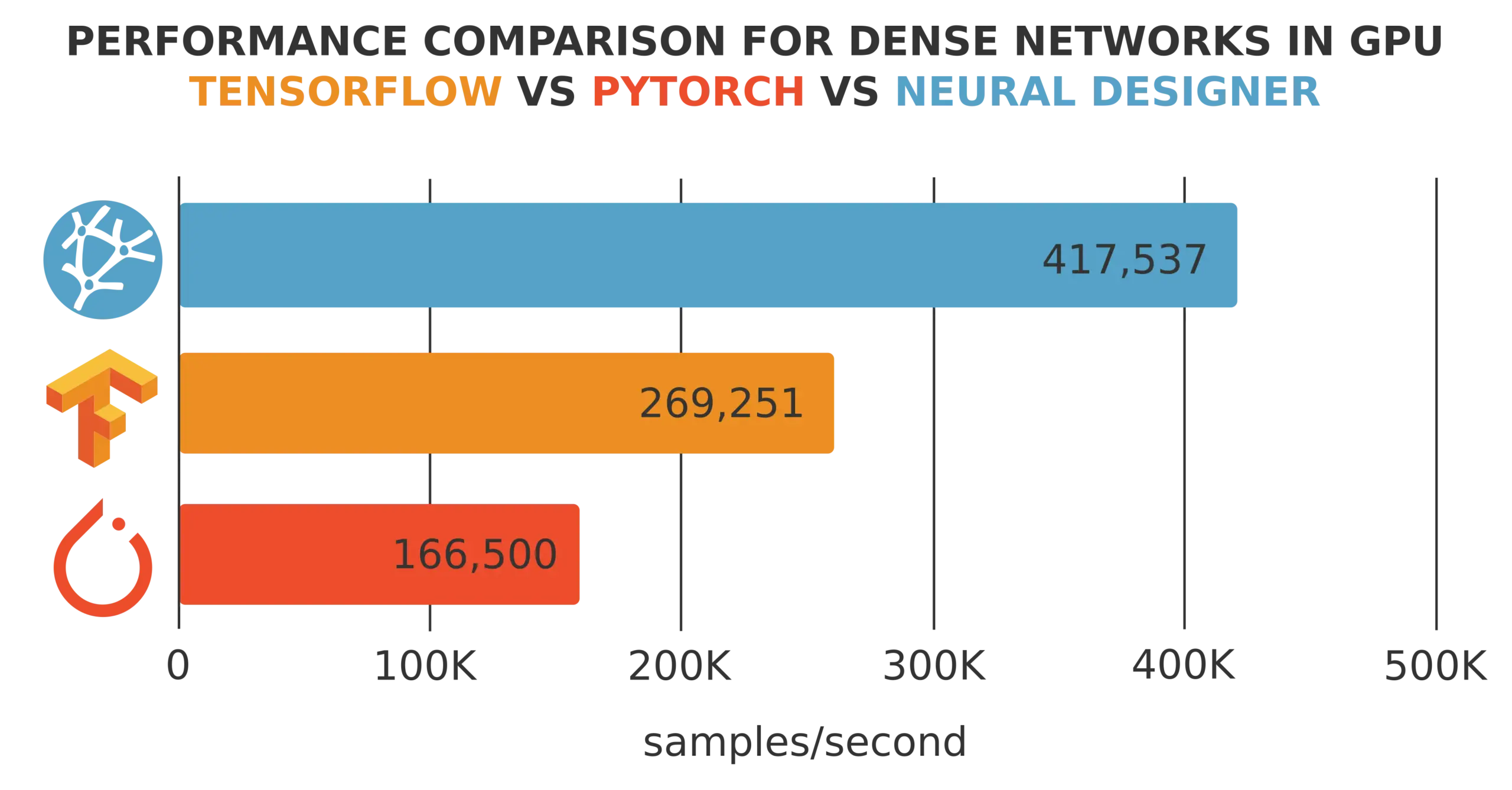
The following figure illustrates the results of a training speed test conducted on two platforms.
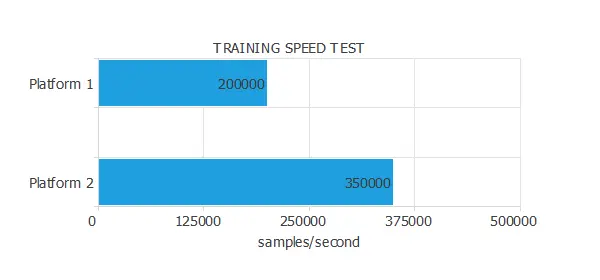
As we can see, the training speed of Platform 1 is 200,000 samples/second, while that of Platform 2 is 350,000 samples/second.
Therefore, we can say that the training speed of Platform B is 1.75 times the capacity of Platform A.
To illustrate this, consider a dataset with 1,000,000 training samples and an optimization algorithm that runs for 1,000 epochs. The training time for Platform A is 1 hour, 23 minutes, and 20 seconds, and the training time for Platform B is 00 hours, 47 minutes, and 37 seconds.
Model precision tests
The primary objective of machine learning is to develop models that achieve high accuracy.
We can define precision as the mean error of a model against a testing data set.
The precision of a machine learning platform depends on numerous factors:
- The optimization algorithm with which it has been trained (HPC).
- The programming language in which it is written (C++, Java, Python…).
- The high-performance computing (HPC) techniques that it implements (CPU parallelization, GPU acceleration…).
We follow the next steps to compare the precision of different machine learning platforms:
- Select a reference computer (e.g., CPU, GPU, RAM).
- Choose a reference dataset (variables and sample number).
- Choose a reference model (number of layers, number of neurons…).
- Choose a reference training strategy (loss index, optimization algorithm…).
- Choose a stopping criterion (loss goal, epochs number, maximum time…).
A dataset here should allow us to reach an error of 0.
The following table illustrates the result of an accuracy test with two platforms:
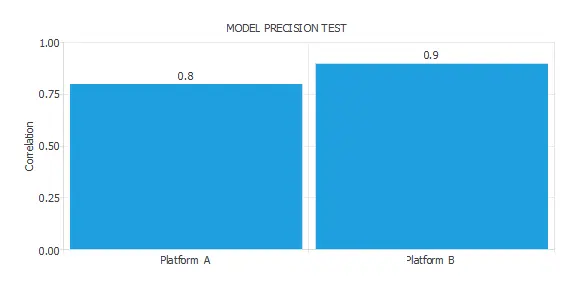
As we can see, Platform A can build a model with a correlation of 0.8. On the other hand, Platform B can build a model with a correlation of 0.9. Therefore, we can say that the precision of Platform B is 1.12 times bigger than that of Platform A.
Inference speed tests
In many applications, particularly those requiring real-time performance, the model’s response time is a critical factor. Indeed, an inference time of a few milliseconds can make the model impractical.
The inference speed can be defined as the time required to calculate the model’s outputs as a function of its inputs. To measure this metric, we use the number of samples per second.
The inference speed of a machine learning platform depends on numerous factors.
- The programming language in which it is written (C++, Java, Python…).
- The high-performance computing (HPC) techniques that it implements (CPU parallelization, GPU acceleration…).
To compare the inference speed of machine learning platforms, we follow the next steps:
- Select a reference computer (e.g., CPU, GPU, RAM).
- Choose a reference input set (variables and samples number).
- Choose a reference model (number of layers, number of neurons…).
The following figure illustrates the results of an inference speed test conducted on two platforms.
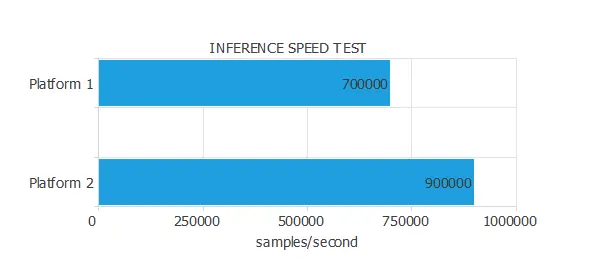
As we can see, in one second, Platforms A and B can calculate the outputs for 700,000 and 900,000 inputs, respectively.
Therefore, we can say that the inference speed of Platform B is 1.28 times bigger than that of Platform A.
Conclusions
This post aims to define the most important KPIs (critical key performance indicators ) in machine learning platforms for benchmarking in the industry.
It also describes the most relevant factors affecting those key performance indicators.
Finally, it describes how to design and measure performance tests for data capacity, training speed, model precision, and inference speed.
The data science and machine learning platform Neural Designer utilizes high-performance techniques to maximize productivity.
You can download Neural Designer now and try it for free.