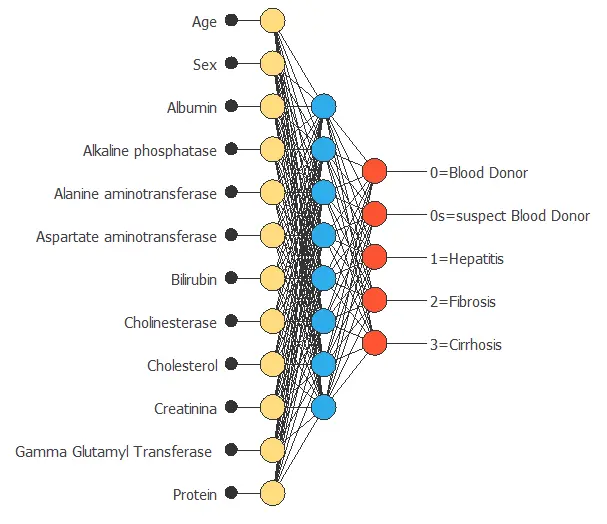
Introduction
In machine learning, samples represent all variables in the dataset and are divided into training, validation, and test samples.
Labeled examples have a label that describes or characterizes the example, and unlabeled examples have no associated feature.
The samples are the rows of the data matrix.
Let $p$ and $q$ be the number of rows and columns in the data matrix.
A sample is a vector $u \in {R}^{q}$. In this regard, the data matrix contains $p$ samples,
\begin{eqnarray}
u_{i}:=row_{i}(d), \quad i=1,\ldots,p.
\end{eqnarray}
Designing a neural network to memorize a data set is not helpful.
Instead, we want the neural network to perform accurately on new data, that is, to generalize.
To achieve that, we divide the data set into three different subsets:
- The first subset is the training set. We use it for constructing different candidate models.
- The second subset is the selection set, used to select the model exhibiting the best properties.
- Finally, the third subset is the testing set used to validate the final model.
The following figure illustrates the potential applications of a sample within a dataset.
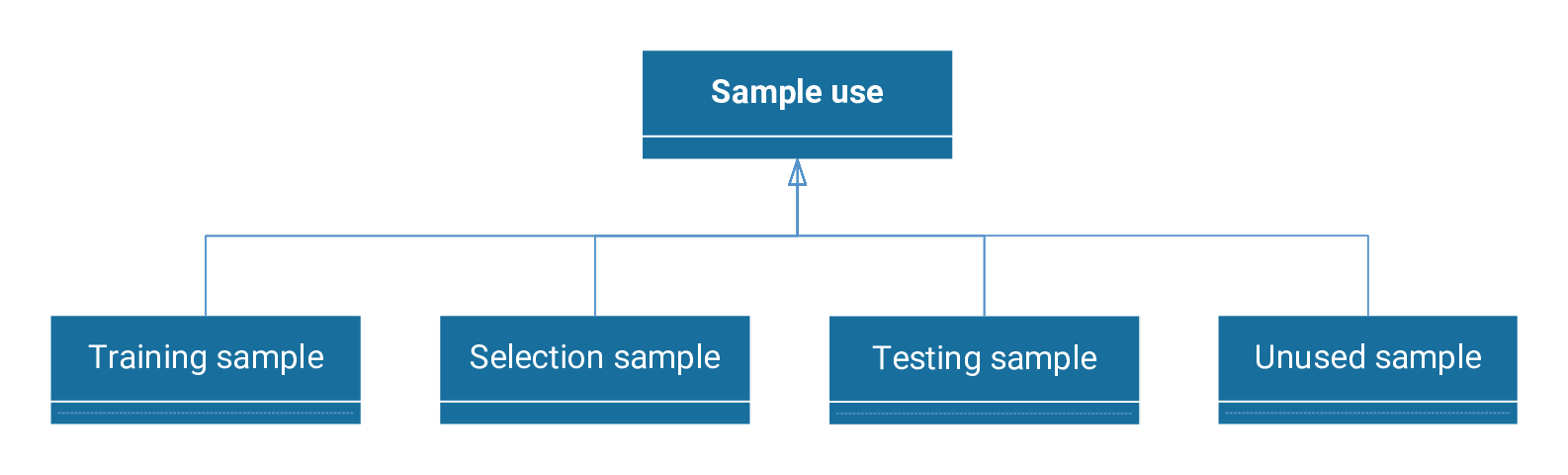
Usually, 60% of the samples are used for training, 20% for selection, and 20% for testing.
The sample splitting might be performed in sequential order or randomly.
Next, we provide a detailed description of the use of the training, selection, and testing samples.
Contents
2. Training Samples
Training samples are the dataset used to train the model, allowing it to learn the features and patterns of the data.
In each epoch, the training data is repeatedly fed into the neural network architecture, and the model continues to learn the features of the data.
The training set should have a diverse input set so that the model is trained in all scenarios and can predict any unseen data samples that may arise.
3. Selection samples
The selection or validation set is the dataset used to validate the performance of our model during training.
This selection process provides information that helps us tune the model’s hyperparameters and configuration accordingly.
The model is trained on the training set, and its performance is evaluated on the validation set after each epoch.
We use the selection samples for choosing the neural network with the best generalization properties.
4. Testing samples
The test set is a set of data used to test how the model works after training is complete.
It provides an unbiased metric for determining model performance in terms of accuracy, precision, etc.
5. Unused samples
Some samples might distort the model instead of providing helpful information to the model. For example, outliers in the data can cause the neural network to perform poorly. To fix those problems, we set some samples to $unused$. We can also set repeated samples to $unused$ since they provide redundant information to the model.
In this regard, we can define the following samples using a vector,
\begin{eqnarray}
sample\_use = \{ training \lor selection \lor testing \lor unused \}^{p}.
\end{eqnarray}
The size of this vector is $p$, the number of samples in the data set.
Note that a sample cannot have two uses at the same time. For example, we cannot use a sample to $train$ and $test$ a model.
When designing a model, we usually test different configurations, i.e., we usually build candidate models with different architectures and compare their performance.
The first step in building several models is to train different models with the training samples.
We then select the one that performs best with the selection samples.
Finally, we test their capabilities with the test samples.
Example: Car price assignment
An automotive company wants to understand the factors that affect the price of cars in the market.
For this study, we gathered an extensive data set of different types of cars on the market to create the model.
The data set has 205 samples. Sixty percent of the samples will be for training, 20% for selection, and 20% for testing.
The first step is to build several models and train them with the training samples.
For the first model, we utilize the 25 variables in the dataset. The following table shows the training error and selection error.
| training error | selection error |
|---|---|
| 0.0006 | 0.1630 |
For the second model, we have chosen to use 10 variables from the dataset that coincide with those with the highest correlation with the target variable. The following table shows the training error and selection error.
| training error | selection error |
|---|---|
| 0.0296 | 0.1760 |
We then select the one that performs best with the selection samples.
The selection tests validate the performance of our model during training.
The best-performing model is the first because the selection error is smaller.
Finally, we tested the chosen model’s capabilities using the test samples.
Conclusions
The samples are the rows of the data matrix and are divided into training, selection, and test samples.
From the training samples, we train the model. We then select the best-performing model using the selection samples and, finally, test its capabilities with the test samples.
Tutorial video
You can watch the video tutorial to help you complete this article.
References
- Kaggle Machine Learning Repository. Car Price Assignment Data Set.