The mathematics behind Artificial Intelligence can be challenging to understand.
It is essential to comprehend them to apply machine learning algorithms properly.
The interpretation of the results also requires an understanding of mathematics and statistics.
This post explains the learning problem of neural networks from a mathematical perspective.
In particular, from the perspective of functional analysis and variational calculus.
Contents
1. Preliminaries
First, we will define some mathematical concepts.
Function
A function is a binary relation between two sets that associates each element of the first set to exactly one element of the second set.
$$begin{align*}
y colon X &to Y\
x &mapsto y(x)
end{align*}$$
Function space
A function space is a normed vector space whose elements are functions. For example, $C^1(X, Y)$ is the space of continuously differentiable functions, or $P^3(X, Y)$ is the space of all polynomials of order 3.
Optimization problem
An optimization problem involves finding a vector that minimizes a given function.
| $$Find x^* in X such that f(x) is minimum.$$ |
For example, let’s look at the function $f(x)=x^2$.
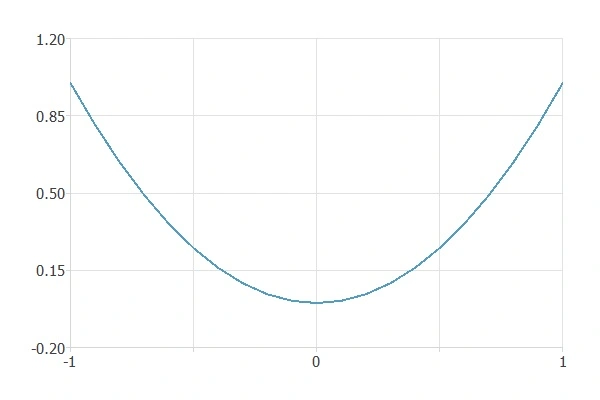
In this case, the minimum is at $x=0$.
Functional
A functional correspondence assigns a unique number to each function belonging to a specific class.
$$begin{align*}
F colon V &to R\
y(x) &mapsto F[y(x)]
end{align*}$$
Variational problem
A variational problem consists of finding a function that minimizes a functional.
| $$Find x^* in X such that f(x) is minimum.$$ |
For example, given two points $A$ and $B$, we consider the functional of length.
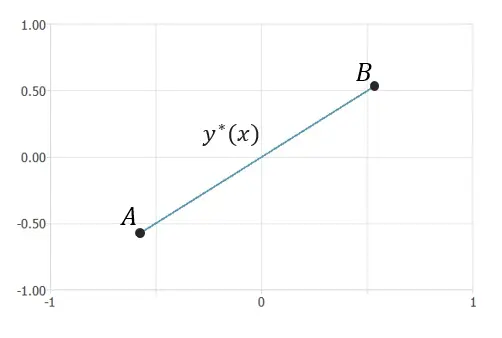
The function $y^*(x)$ that minimizes the length between the two points is a straight line.
Neural network
A neural network is a biologically inspired computational model consisting of a network architecture composed of artificial neurons. Neural networks are a powerful technique for solving approximation, classification, and forecasting problems.
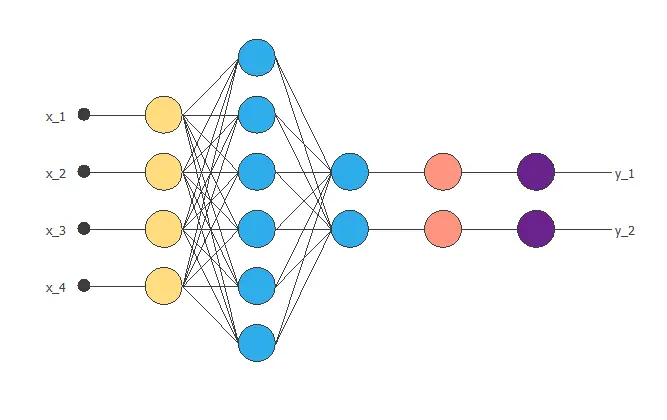
This diagram shows a neural network with four inputs and two outputs.
2. Learning problem
We can express the learning problem as finding a function that causes some functional to assume an extreme value. This functional, or loss, index defines the task the neural network must perform and provides a measure of the quality of the representation that the network needs to learn. The choice of a suitable loss index depends on the particular application.
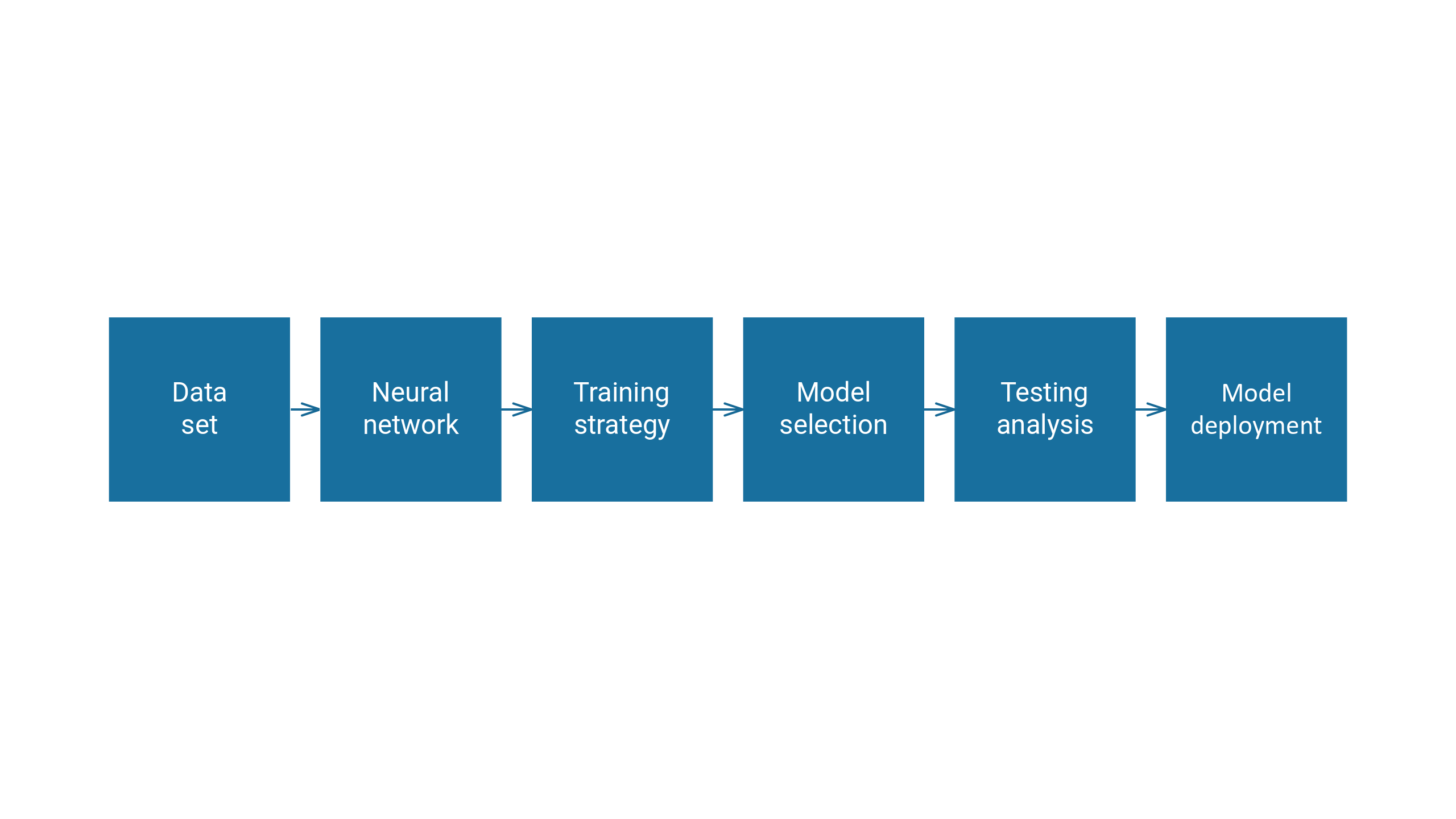
Here is the activity diagram.
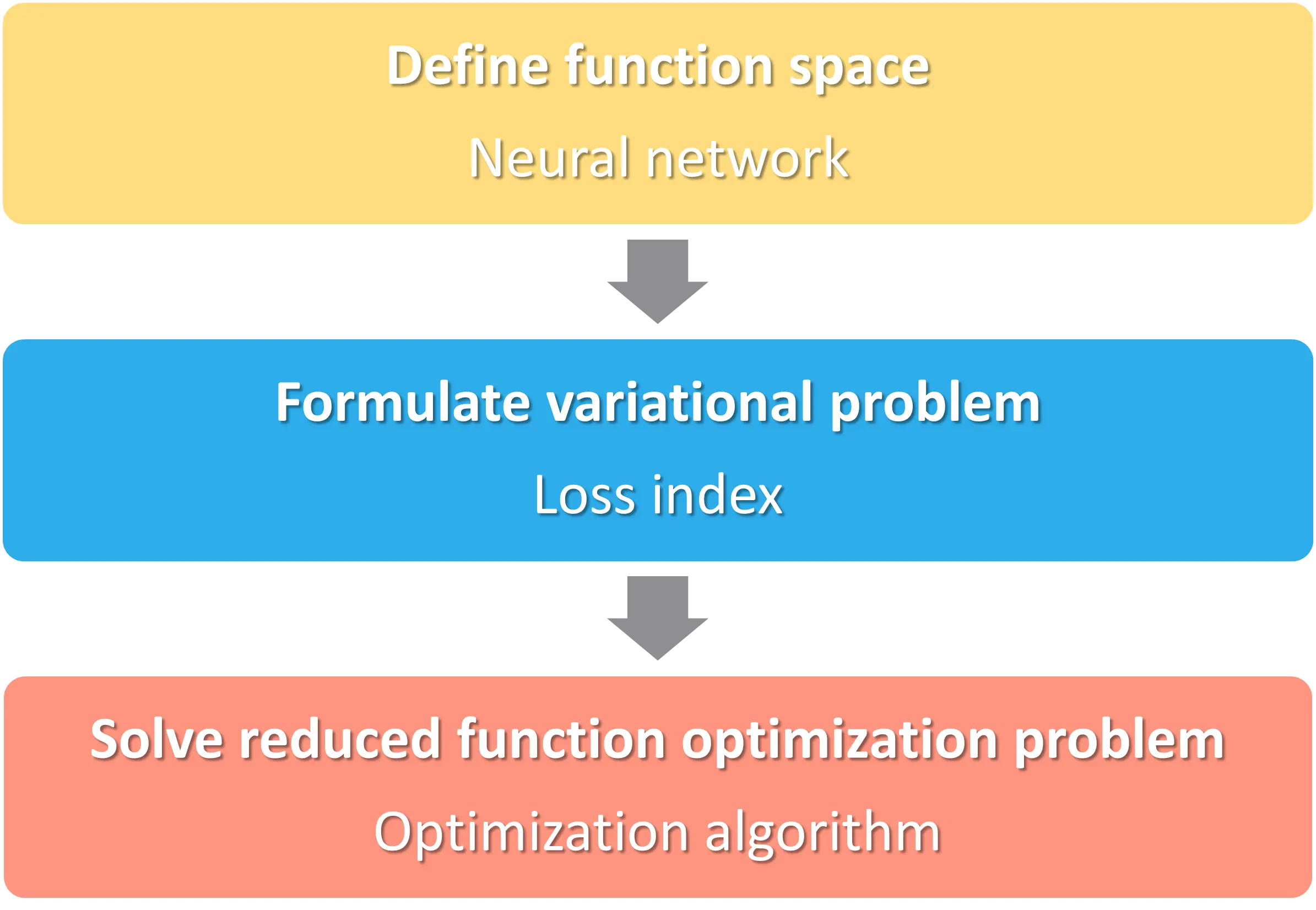
We will explain each step individually.
2.1. Neural network
A neural network spans a function space, which we will call $V$. It is the space of all the functions that the neural network can produce.
$$begin{align*}
y colon X subset R^n &to Y subset R^m\
x &mapsto y(x;theta)
end{align*}$$
This structure contains a set of parameters. The training strategy will then adjust the parameters to enable the system to perform specific tasks.
Each function depends on a vector of free parameters $theta$. The dimension of $V$ is the number of parameters in the neural network.
For example, we have a neural network here. It has a hidden layer with a hyperbolic tangent activation function and an output layer with a linear activation function. The dimension of the function space is 7, the number of parameters in this neural network.
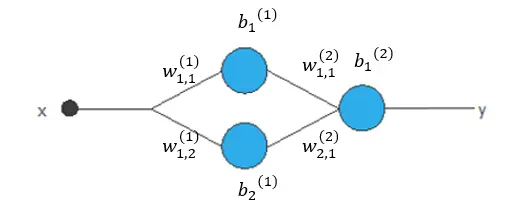
The elements of the function space are of the following form.
$$y(x;theta)=b_1^{(2)}+w_{1,1}^{(2)}tanh(b_1^{(1)}+w_{1,1}^{(1)}x)+w_{2,1}^{(2)}tanh(b_2^{(1)}+w_{1,2}^{(1)}x)$$
Here, we have different examples of elements of the function space.
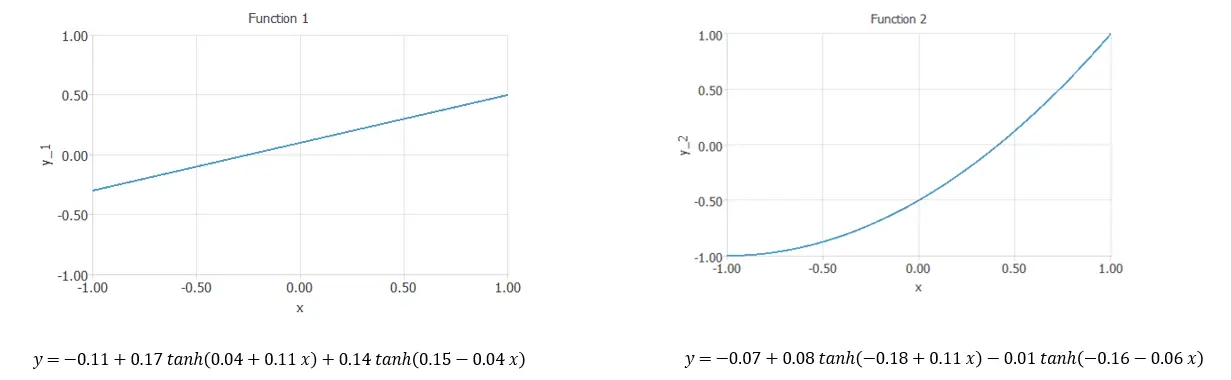
They both have the same structure but different values for the parameters.
2.2. Loss index
The loss index is a functional that defines the task for the neural network and provides a measure of quality. The choice of the functional depends on the application of the neural network. Some examples are the mean squared error or the cross-entropy error. In both cases, we have a dataset with $k$ points $(x_i,y_i)$, and we are looking for a function $y(x, \ theta)$ that fits them.
- Mean squared error: $E[y(x;theta)] = frac{1}{k} sum_{i=1}^k (y(x_i;theta)-y_i)^2$
- Cross-entropy error: $E[y(x;theta)] = – frac{1}{k} sum_{i=1}^k y(x_i;theta) log(y_i)$
We formulate the variational problem, which is the learning task of the neural network. We look for the function $y^*(x;theta^*) in V$ for which the functional $F[y(x;theta)]$ gives a minimum value. In general, we approximate the solution with direct methods.
Let’s see an example of a variational problem. Consider the function space of the previous neural network. Find the element $y^*(x;theta)$ such that the mean squared error functional, $MSE$, is minimized. We have a series of points, and we are looking for a function that will fit them.
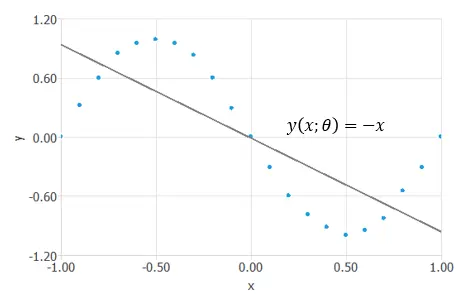
We have taken a random function $y(x;theta)=-x$ for now, the functional $MSE[y(x;theta)]=1.226$ is not minimized yet.
Next, we will examine a method for solving this problem.
2.3. Optimization algorithm
The objective functional $F$ has an associated objective function $f$.
$$begin{align*}
f colon Theta subset R^d &to R\
theta &mapsto f(theta)
end{align*}$$
We can reduce the variational problem to a function optimization problem. We aim to find the vector of free parameters $theta^* in Theta$ that will make $f(theta)$ have its minimum value. With it, the objective functional achieves its minimum.
The optimization algorithm will solve the reduced function optimization problem. There are several methods for the optimization process, including the Quasi-Newton method and the gradient descent.
Let’s continue the example from before. We have the same set of points and are looking for a function that will fit them. We have reduced the variational problem to a function optimization problem. To solve the function optimization problem, the optimization algorithm searches for a vector $theta^*$ that minimizes the mean squared error function.
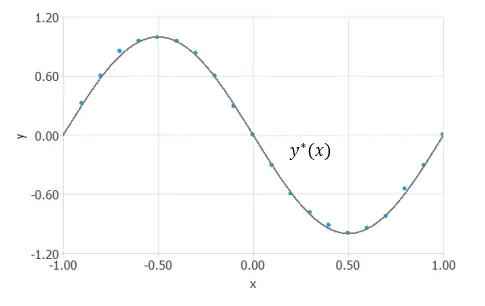
After finding this vector $theta^*=(−1.16,−1.72, 0.03,2.14,−1.67,−1.72, 1.24)$, for which $mse(theta^*)=0.007$,
we obtain the function $y^*(x;theta^*)=−1.16−1.72tanh(0.03+2.14x)−1.67tanh(−1.72+1.24x)$ that minimizes the functional. This is the solution to the problem.
3. Conclusions
We have explained neural networks from the perspective of variational calculus.
The neural network spans a parameterized function space. In this space, we formulate the variational problem. We must minimize a functional to solve it. To do so, we reduce it to a function optimization problem. This is achieved through an optimization algorithm, and we obtain the desired function.
4. Video
Watch this video to gain a deeper understanding of the learning problem in neural networks.