Customer targeting is the process of analyzing customer features (such as age, education, interests, and spending habits) to select those customers who are more prone to a target product or service.
Contents
Advanced analytics
The volume, variety, and velocity of information stored in organizations have increased significantly.
The intelligent analysis of these data can differentiate companies that adopt this technique.
However, most companies only perform descriptive analyses of their data to understand past trends.
These organizations can get more value from their data by using more sophisticated techniques.
This process is known as advanced analytics, and it is illustrated in the following figure.
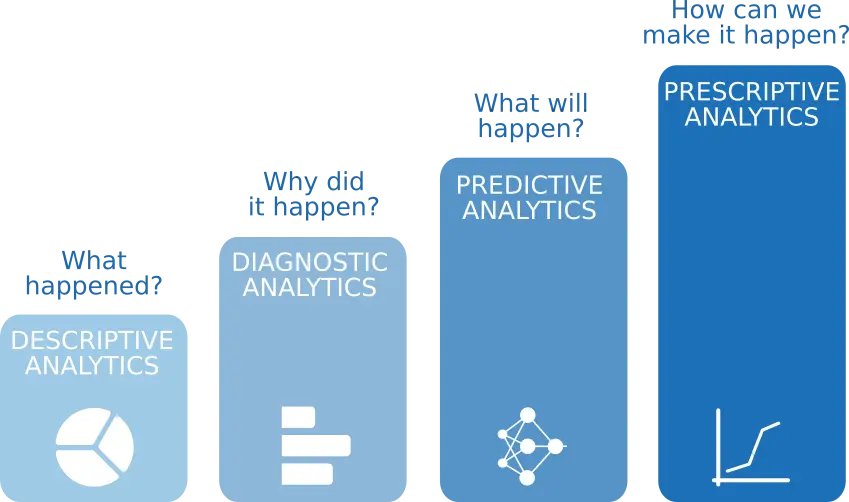
As we can see, advanced analytics comprises 4 steps:
- Descriptive analytics: It answers the question of what happened?
- Diagnostic analytics: It answers the question of why did it happen?
- Predictive analytics: It answers the question of what will happen?
- Prescriptive analytics: It answers the question of how we can make it happen?
As we will see in this post, advanced analytics enable us to select individual targets, resulting in increased profitability.
Case study
To illustrate the advanced analytics process, we will apply descriptive, diagnostic, predictive, and prescriptive analytics to a real dataset from a banking institution.
This case study is solved with the data science and machine learning platform Neural Designer. The following figure is a screenshot of this software.
The goal is to select customers with a similar profile to those who have purchased the product and include them in a targeted marketing campaign.
The dataset consists of 1,000,000 clients (or instances), each with 500 features (or variables).
The following table summarizes the characteristics of the data set.
| Number of customers: | 1,000,000 |
|---|---|
| Number of features: | 500 |
| Total data: | 500,000,000 |
Some types of variables in our data set are the following:
- Customer variables: Sex, age, nationality…
- Company variables: Company reputation, number of web visits, marketing expenses…
- Product variables: Price, conditions…
- Engagement variables: Last purchase, number of purchases, total amount spent…
Please note that the dataset has been anonymized to protect the company’s privacy.
The target variable is the purchase of a given product or service. This is a binary variable with a value of 1 if the customer has purchased the product and 0 if they haven’t.
Descriptive analytics
Descriptive analytics is the first stage of advanced analytics. It answers the question What happened?
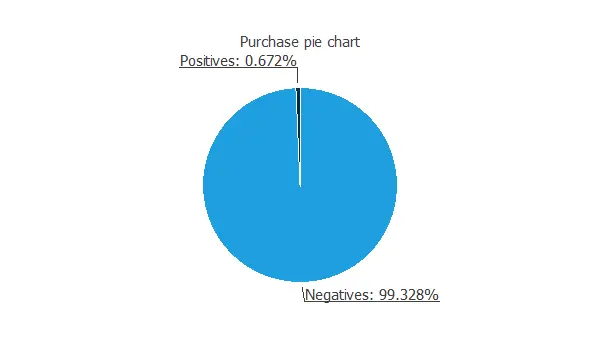
It is essential to know the acceptance ratio of our product or service among our clients.
The next pie chart shows the distribution of the purchase variable.
Diagnostic analytics
Diagnostic analytics is the second phase of advanced analytics. It answers the question Why did it happen?
This phase provides us with insights into the factors that impact our decision to purchase a product or service.
To discover that, we can calculate the input-target correlations.
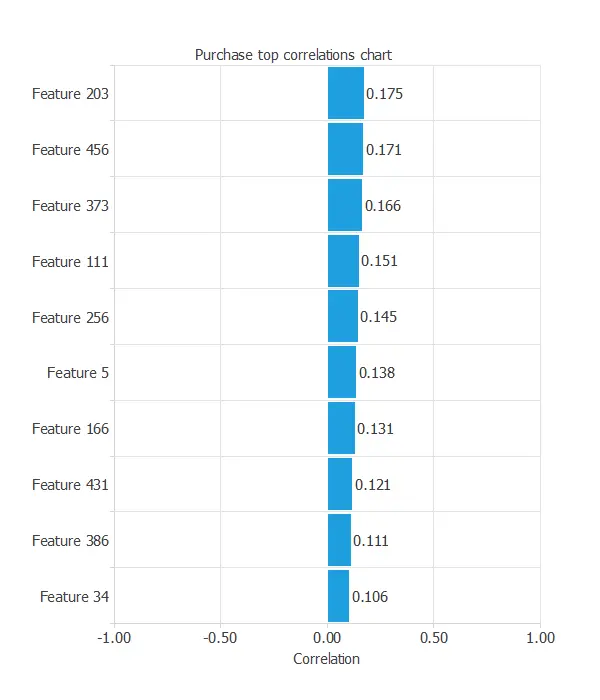
All input variables show low correlation with the target (below 20%), meaning no single feature strongly drives purchases.
This indicates a complex problem where multiple factors matter.
The most correlated features are those linked to customer engagement.
Predictive analytics
Predictive analytics is the third stage of advanced analytics. It answers the question of “What will happen?
Neural networks are one of the most powerful techniques for building predictive models. These are mathematical algorithms that discover patterns from data by emulating the functioning of the human brain.
For our case study, the neural network takes as input the customer, company, product, and engagement factors and produces as output the probability that the customer will purchase the product.
The following graph illustrates this neural network.
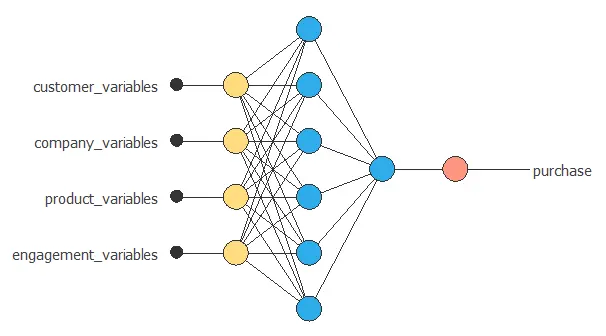
As we can see, neural networks can analyze any number and type of factors.
Prescriptive analytics
Prescriptive analytics is the fourth and last step of advanced analytics. It answers the question How can we make it happen?
After building the predictive model, we exploit it to maximize our benefits. To achieve this, we design a marketing campaign targeting customers with the highest likelihood of purchasing the product.
We will assume that the unit cost per contact with each potential customer is 10 USD and that the unit benefits if they buy the product are 1,000 USD.
The profit chart simulates the benefit without applying the predictive model (grey line) and applying it (blue line).
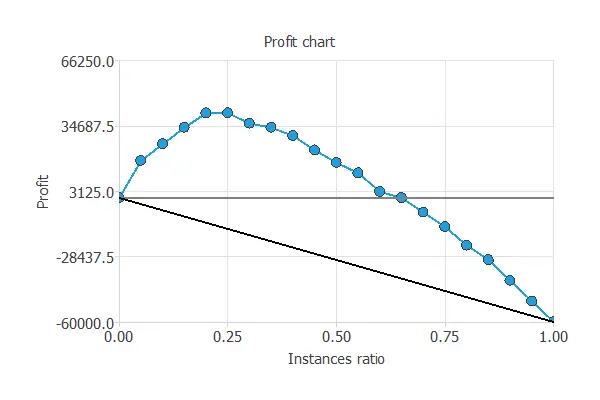
Without the predictive model, contacting more clients leads to losses due to the low conversion rate (0.6%).
By focusing only on the 20% most likely to buy, the model turns losses of about -$15,000 into profits of around $40,000.
Conclusions
Advanced Analytics analyzes all types of data to target the most profitable clients accurately.
This type of personalized marketing can significantly increase a company’s profits.
Neural Designer is a data science and machine learning platform that allows you to apply advanced analytics easily.
You can download a free trial here.



