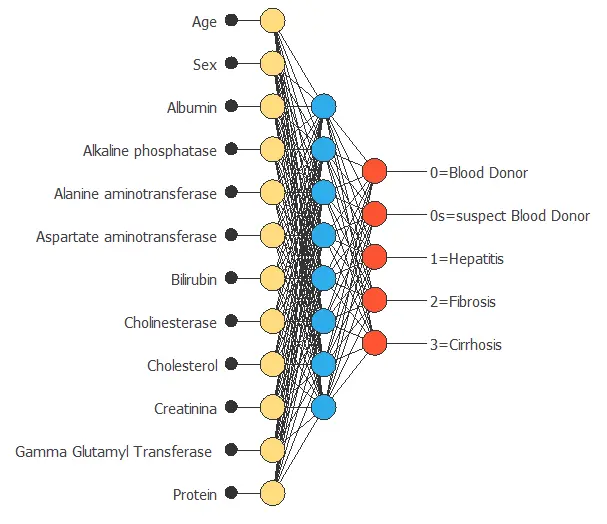
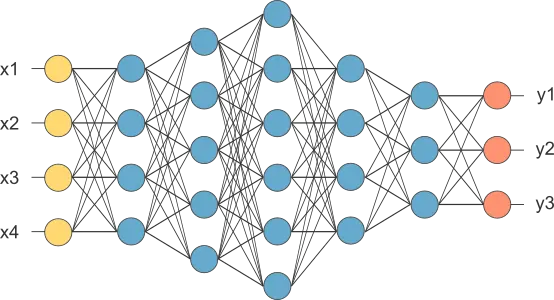
Feature selection algorithms help you choose the most relevant variables for building machine learning models.
In this post, we present the model selection problem and describe the algorithms most commonly used in practice.
Neural Designer implements all the model selection algorithms described here.
To use these algorithms in practice, you can download the free trial.
Contents
Problem formulation
Model selection helps you find the neural network topology that achieves the best generalization.
The selection error is defined as the error of a neural network on new data, and it measures the model’s ability to make accurate predictions in unseen cases.
Input selection algorithms aim to identify the optimal subset of inputs.
By performing input selection, you can improve prediction quality by extracting the subset of variables that truly influence a given physical, biological, social, or other process.
Growing inputs
The growing inputs method starts by calculating every input’s correlation with every output in the neural network.
The growing inputs method begins with the most correlated input and continues to add well-correlated variables until the selection error starts increasing.
Pruning inputs
The pruning input method also starts by calculating the correlations among every input and output in the neural network.
The pruning inputs algorithm begins by considering all variables in the dataset and then removes the inputs with minimal correlation with the outputs.
Genetic algorithm
A different class of input selection method is the genetic algorithm.
This stochastic method is based on the mechanics of natural genetics and biological evolution.
The genetic algorithm implemented includes several methods to perform fitness assignment, selection, crossover, and mutation operators.
The following figure shows a simplified flow diagram of the genetic algorithm.
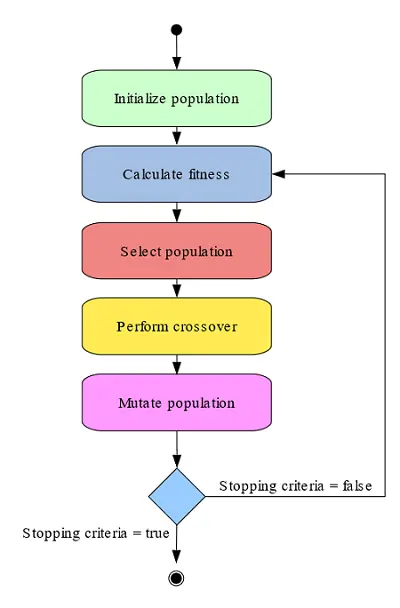
The genetic algorithm starts with a population of different subsets of variables.
In every generation, the fitness of every individual in the population is computed as the selection error for that subset of inputs.
Then, the method evolves the population by selecting some individuals to generate the new population, performing a crossover with the selected population, and mutating the offspring generated during the crossover.
Conclusions
However, model selection algorithms are computationally expensive, which is a significant drawback in terms of performance.
Neural Designer includes an advanced model selection framework capable of representing very complex data sets.
This system adds significant value to data scientists, providing them with results in a way previously unachievable.