Exploratory data analysis
The variables are of two types:
- Input variables: these are the predictors of the model (age, cytology, HPV, biopsy, p16/ki67, and smoke).
- Target variables: these are the variables to be predicted (PROGNOSIS).
The following chart illustrates the use of the variables. As we can see, our data set has six input variables and one target variable.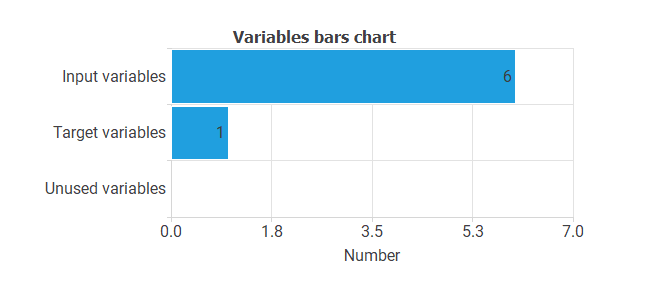
Instances
On the other hand, cases can be of three types:
- Training cases are used to build different prognostic models with different topologies.
- Selection cases are used to select the prognostic model with the best predictive capabilities.
- Test cases are used to validate the performance of the prognostic model.
The following pie chart details the uses of all cases in the data set.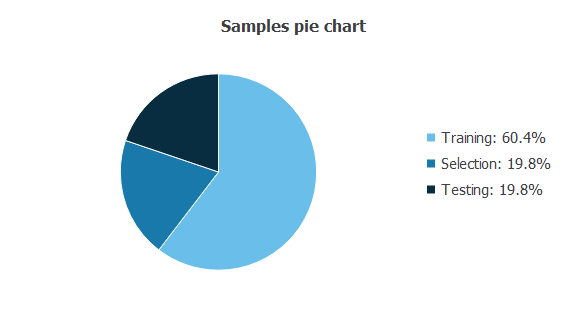
There are 119 training cases (60.4%), 39 generalization cases (19.8%), and 39 validation cases (19.8%).
Statistics
The bare statistics provide valuable information when designing a model since they tell us the ranges of the variables.
The table below shows the minimums, maximums, means, and standard deviations of all variables in our data set.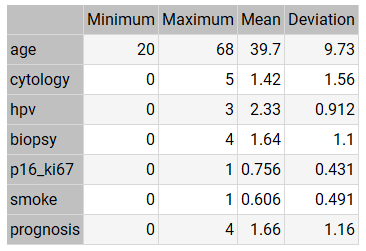
As we can see from the statistics:
- The mean AGE of the patients is around 40 years.
- The mean CYTOLOGY value is low (between ASC-US and ASC-H).
- The mean HPV value is high (between OTHER HIGH RISK and HPV 16-18).
- The mean value of BIOPSY is neither high nor low (between CIN I and CIN II).
- The mean value of P16/KI67 is very high.
- The mean value of SMOKE is high.
- The mean value of PROGNOSIS is neither high nor low (between CIN I and CIN II).
The mean PROGNOSIS value (1.66) is slightly higher than the mean BIOPSY value (1.64). This indicates that the mean evolution of patients tends to be stable, although it tends to worsen.
Distributions
Histograms and pie charts show the distribution of the data over its entire range. A uniform or Gaussian distribution of all variables is generally desirable for predictive analysis. Conversely, if the data is uneven, the model will likely be of poor quality.
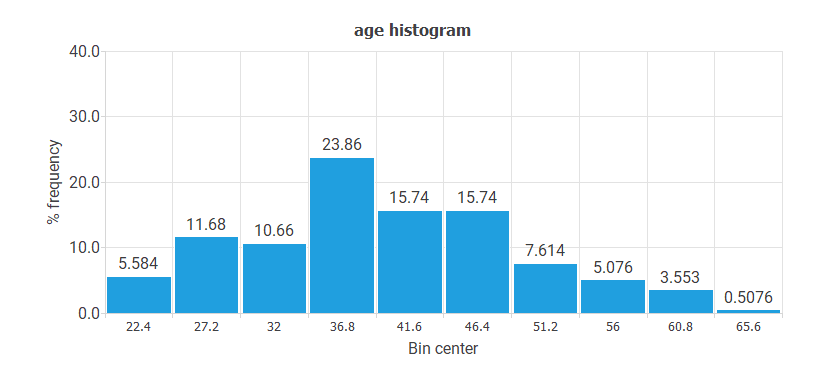
- The following chart shows the histogram for the variable AGE. The abscissa represents the midpoints of the rectangles, and the ordinate represents their corresponding frequencies. This distribution is Gaussian, and the center is at 36.8.
- The following chart shows the histogram for the variable CYTOLOGY. The majority of values correspond to the NORMAL value. The least represented values are ASC-H and AGC.
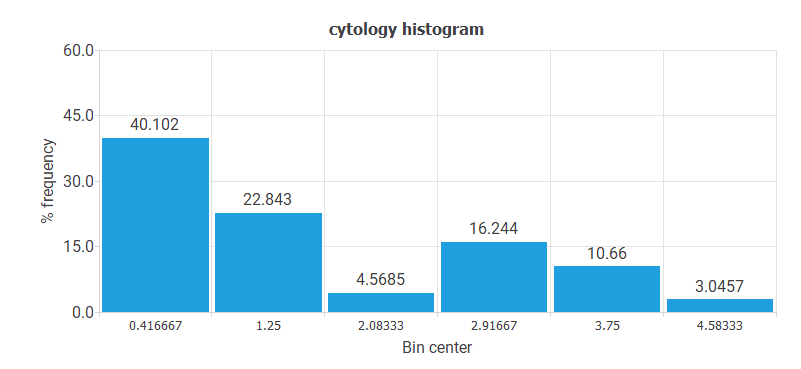
- The following chart shows the histogram for the HPV variable. Here, the majority of cases have HPV 16 or HPV 18 values. The least represented patients are OTHER LOW RISK.
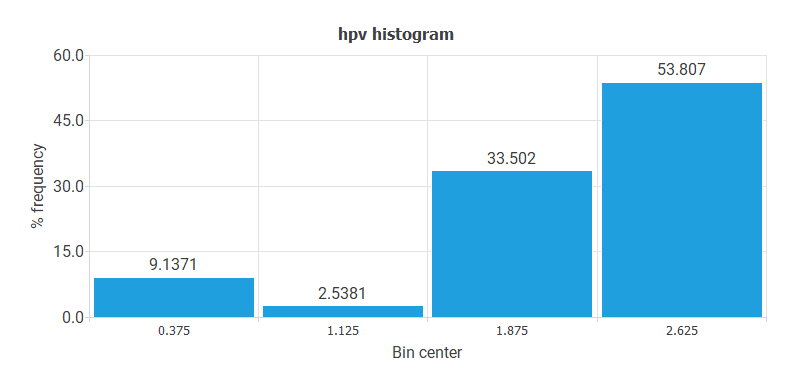
- The following chart shows the histogram for the variable BIOPSY. These data do not have a regular distribution. Indeed, most cases have CIN II-III or CIN III, and very few cases have ADENOCARCINOMA value.
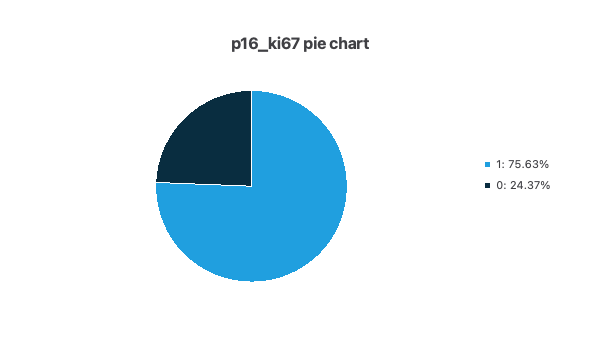
- The following pie chart shows the histogram for the variable P16/KI67. As you can see, there are many more positive than negative cases.
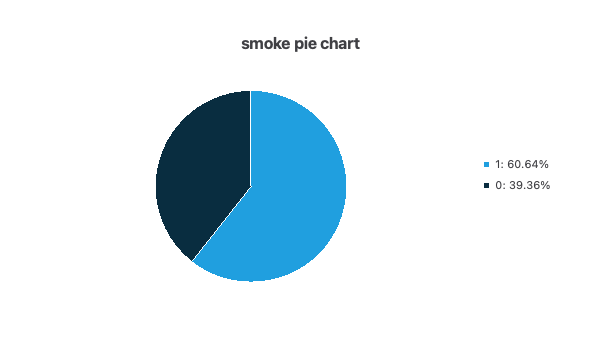
- The following pie chart shows the histogram for the variable SMOKE. As you can see, there are more smokers than non-smokers.
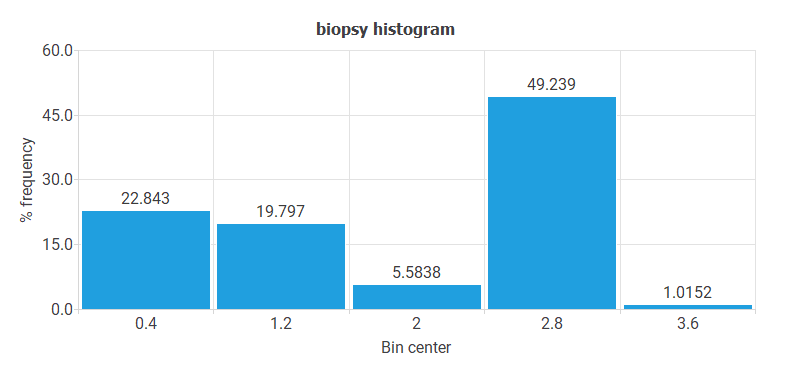
- The following chart shows the histogram for the variable PROGNOSIS. The maximum frequency is for cases with CIN II-III or CIN III, and the minimum is for patients with ADENOCARCINOMA or SQUAMOUS CARCINOMA.
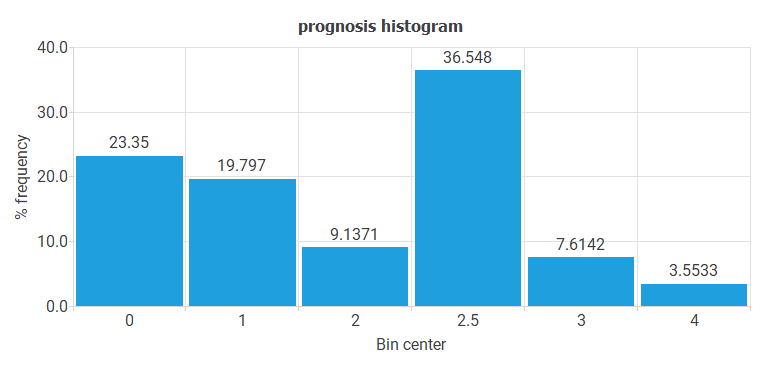
The most important conclusion from all these histograms is that there is little data on the most severe pathologies (ADENOCARCINOMA or SQUAMOUS CARCINOMA). These pathologies are precisely the ones we are most interested in predicting.
Correlations
It might be interesting to look for linear dependencies or correlations between the input and target variables.
Correlations near 1 mean that the prognosis has a strong linear dependence on an input. Conversely, correlations close to 0 indicate no linear relationship between that input and the prognosis.
Note that, in general, target variables depend on many inputs simultaneously, and their relationship is not linear.
The following chart shows the linear correlations between all inputs and the prognosis.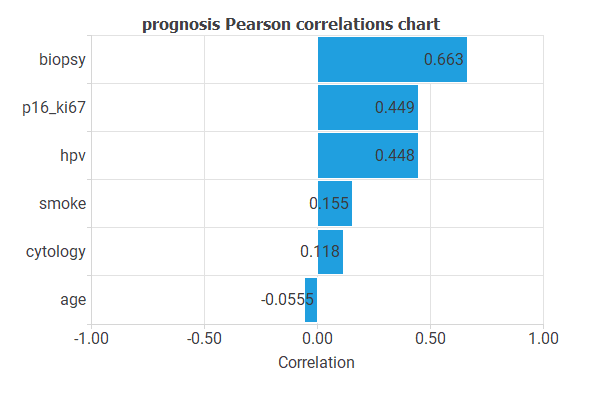
As you can see, the minimum correlations are for the variables AGE and CYTOLOGY, and the maximum correlations are for BIOPSY and P16/KI67.
These correlations can indicate the relative importance of each variable in the prognosis. However, we must be careful with these results since many variables are usually involved in cancer development.
4. Neural network
The neural network defines a function that represents the prognostic model.
The neural network employed here is based on the multilayer perceptron. This type of model is widely used due to its good approximation properties. The multilayer perceptron is extended with a scaling layer connected to the inputs and a de-scaling layer attached to the outputs. These two layers make the neural network always work with normalized values, thus producing better results. In addition to the mentioned layers, there is one final bounding layer. Initially, the number of inputs to the neural network is six (AGE, CYTOLOGY, HPV, BIOPSY, P16/KI67, and SMOKE), and the number of outputs is one (PROGNOSIS).
The generalization study eliminates variables that do not improve the predictive capabilities of the neural network. The complexity of this neural network is two layers of perceptrons. The first layer, or hidden layer, has a sigmoidal activation function. The second layer, or output layer, has a linear activation function. Initially, the number of neurons in the hidden layer is ten, although the generalization study may reduce or increase that number until it finds the optimal complexity.
The following graph is a graphical representation of the neural network. As mentioned above, it contains a scaling layer in yellow, two perceptron layers in blue, a red unscaling layer, and a purple bounding layer.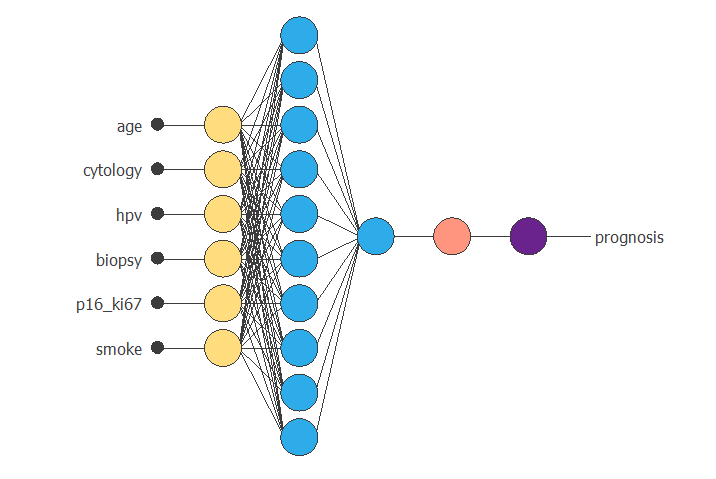
The figure above takes six input values (AGE, CYTOLOGY, HPV, BIOPSY, P16/KI67, and SMOKE) to produce one output value (PROGNOSIS).
Optimization algorithm
The training (or learning) strategy is the procedure that performs the learning process. It is applied to the neural network to obtain the best possible representation.
We use the quasi-Newton method as the optimization algorithm. It is based on Newton’s method but does not require second derivative calculations. Instead, the quasi-Newton method approximates the second derivatives using information from the first derivatives.
The following table shows the operators, parameters, and stopping criteria of the quasi-Newton method used in this study.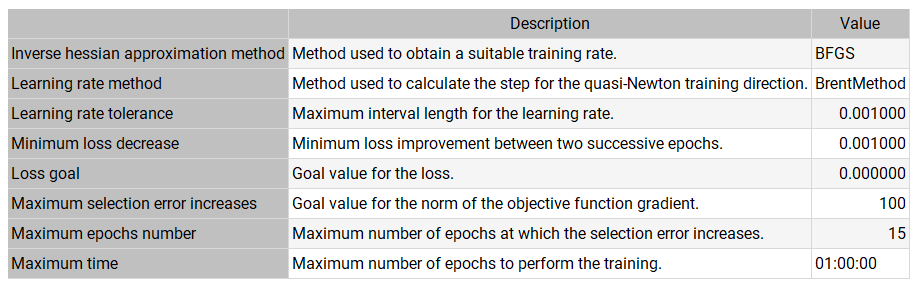
Note that the quasi-Newton method is one of the most widely used training strategies in neural networks.
6. Model selection
To assess the reasonableness of a neural network’s predictive capabilities, we use the selection samples from the data. The error of the neural network on this data indicates the capacity of the model to predict future cases not included in the training set.
The generalization study looks for the neural network with the optimal topology, testing several different models and selecting the one that produces the lowest selection error. In this sense, it trains several neural networks by eliminating input variables and measures the selection error.
The result is that the predictive capabilities improve by eliminating the variable SMOKE. However, by eliminating any other variable, the predictive capabilities worsen.
On the other hand, several neural networks with different complexities have been trained, and the selection error has been measured. The result is an optimal complexity of two neurons in the hidden layer.
The following table shows the training results that produced the lowest selection error.
The final training error is small (0.444), showing that the neural network fits the data. The selection error is also small (0.477), indicating that the neural network has good predictive capabilities.
The training algorithm required 43 epochs, which required 0 s of computation.
The following figure shows the neural network resulting from the lowest generalization error. As we can see, the number of inputs is 5 (CYTOLOGY, HPV, BIOPSY, P16/KI67, and SMOKE), and the number of neurons in the hidden layer is 2. This is the optimal topology for this prognostic problem.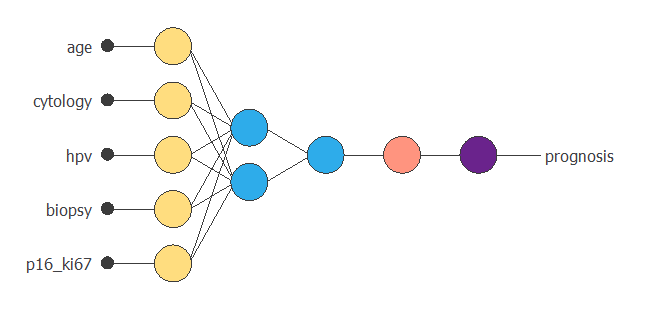
7. Testing analysis
The testing analysis compares the results predicted by the neural network and their respective values in an independent data set. The neural network can move to the production phase if the validation analysis is acceptable.
A standard method to validate the quality of a predictive model is to perform a linear regression analysis between the neural network outputs and the corresponding target values in the data set for an independent validation subset.
This analysis leads to the parameter R2, the correlation coefficient between outputs and targets. If we had a perfect fit (outputs equal to targets), the ordinate at the origin would be 0, the slope would be 1, and the correlation coefficient would be 1.
The following table shows the linear regression parameters for our case study.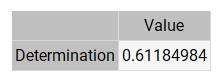
As we can see, the correlation coefficient (0.612) is close to 1. These three values indicate that the neural network predicts the validation data relatively well. However, these predictions are subject to improvement.
The following figure shows the linear regression between the predicted values and their corresponding actual values for the variable PROGNOSIS.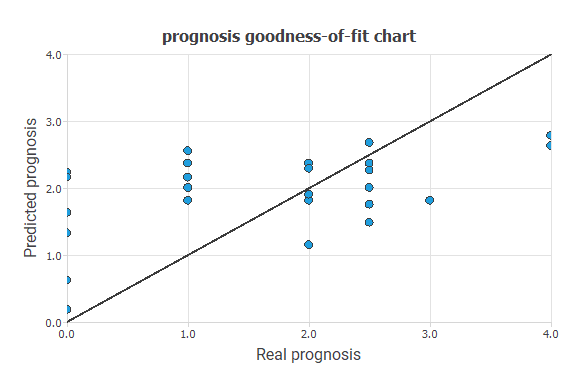
The black line indicates a perfect fit. As we can see, the trend is good, and the dispersion is not very high, although they are also susceptible to improvement.
Error statistics
Exploring the errors made by the neural network in each validation case is convenient. The absolute error is the difference between the target and its corresponding output. The relative error is the absolute error divided by the range of the variable. Finally, the percentage error is the relative error multiplied by 100.
The following table shows the basic error statistics for the validation cases. The mean error is 0.5, half a degree on the PROGNOSIS variable. This is a good indicator of the quality of the diagnoses.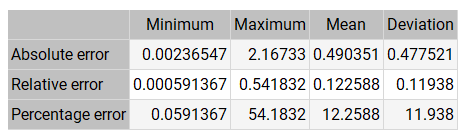
On the other hand, the table above shows some high errors. Therefore, we need to study whether these are isolated cases.
8. Model deployment
Once we have validated the predictive capabilities of the neural network, the cervical pathology unit can use it as a decision support system.
The neural network takes the input values CYTOLOGY, HPV, BIOPSY, P16/KI67, and SMOKE to produce the output PROGNOSIS.
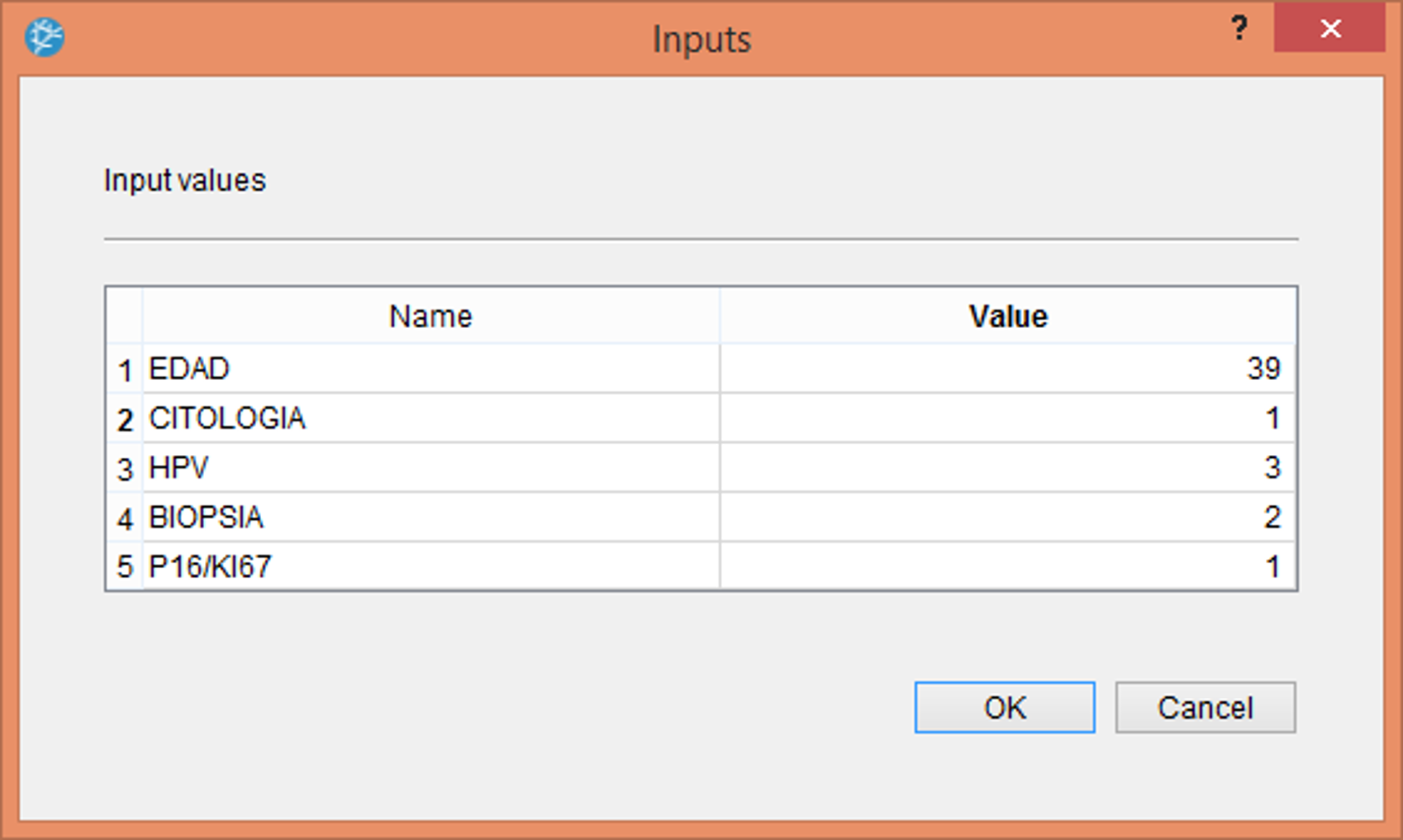
The information here is propagated forward through the scaling layer, the perceptron layers, and the de-scaling layer. The following figure shows the use of the neural network for decision support within the Neural Designer software. This consists of the physician entering the values corresponding to the patient: age, cytological result, HPV type, cervical biopsy result, and p16 positivity.Once we enter the previous values, the program produces a table with the prognosis calculated for that patient, as shown in the following table.
The patient would be 39, ASC-US cytology, HPV 16, CIN II biopsy, and P16/KI67 positive. The PROGNOSIS estimated by the neural network for that patient would be 1.95, corresponding to a CIN II.