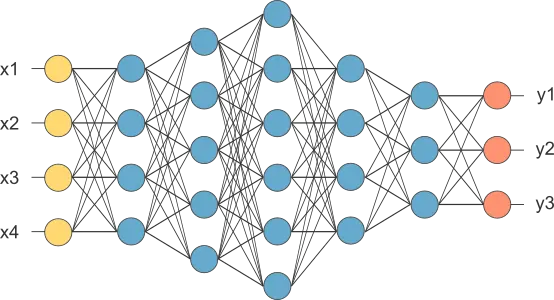
1. Create approximation model
Open Neural Designer. The start page is shown.
Click New approximation model. Then save the project file in the same folder as the data file. Neural Designer now displays the main workspace.
![]()
![]()
2. Configure data set
After creating the model, go to the Data set page and click on the Browse data file button. A file selection dialog will appear. Select the file data.csv and click Finish. The program will automatically load the data and apply the default configuration.
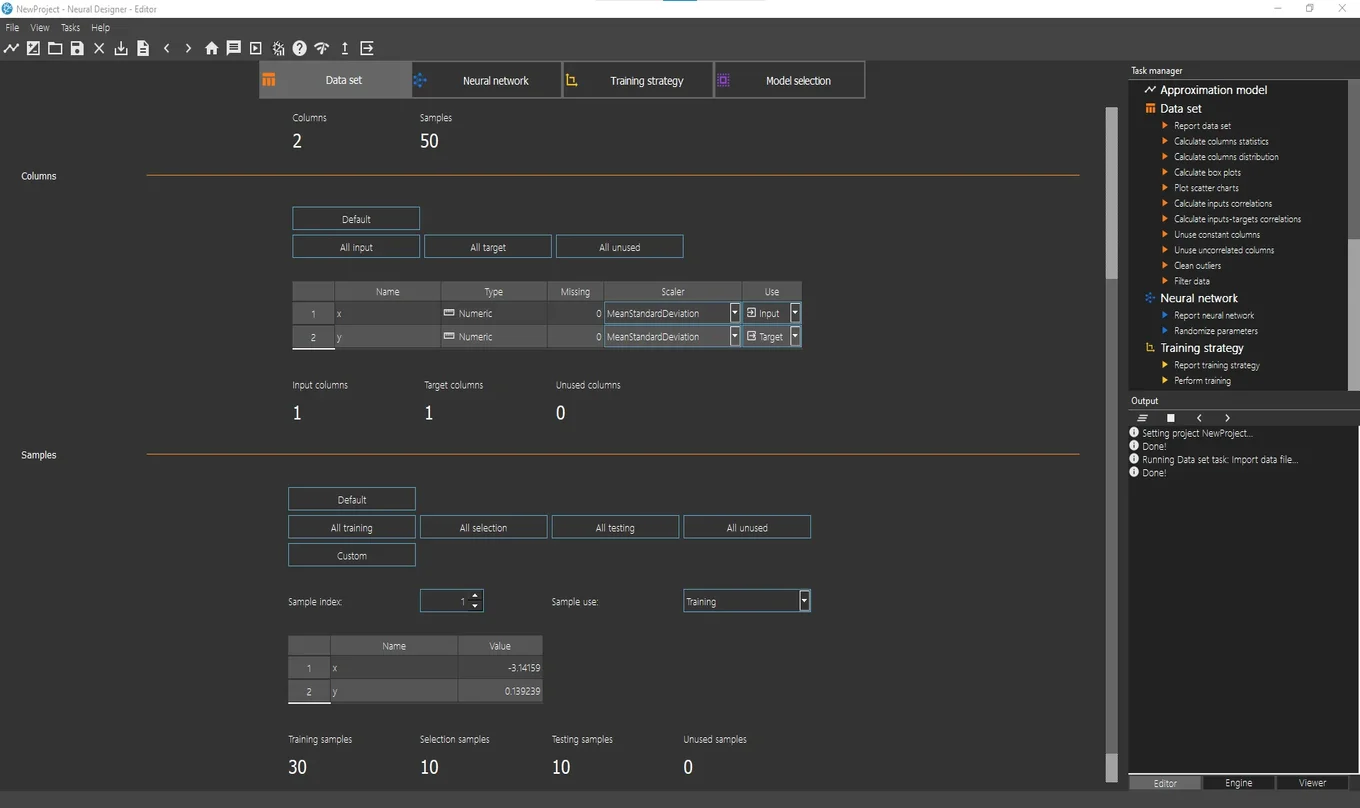
This data set has 2 variables and 50 samples.
Then define how the model will use the instances:
Keep these default values as well.
After configuring the dataset , you can explore it further. For example, open Task Manager > Data set > Plot scatter chart. The Viewer window displays a chart of the data. The plot reveals a sinusoidal shape.
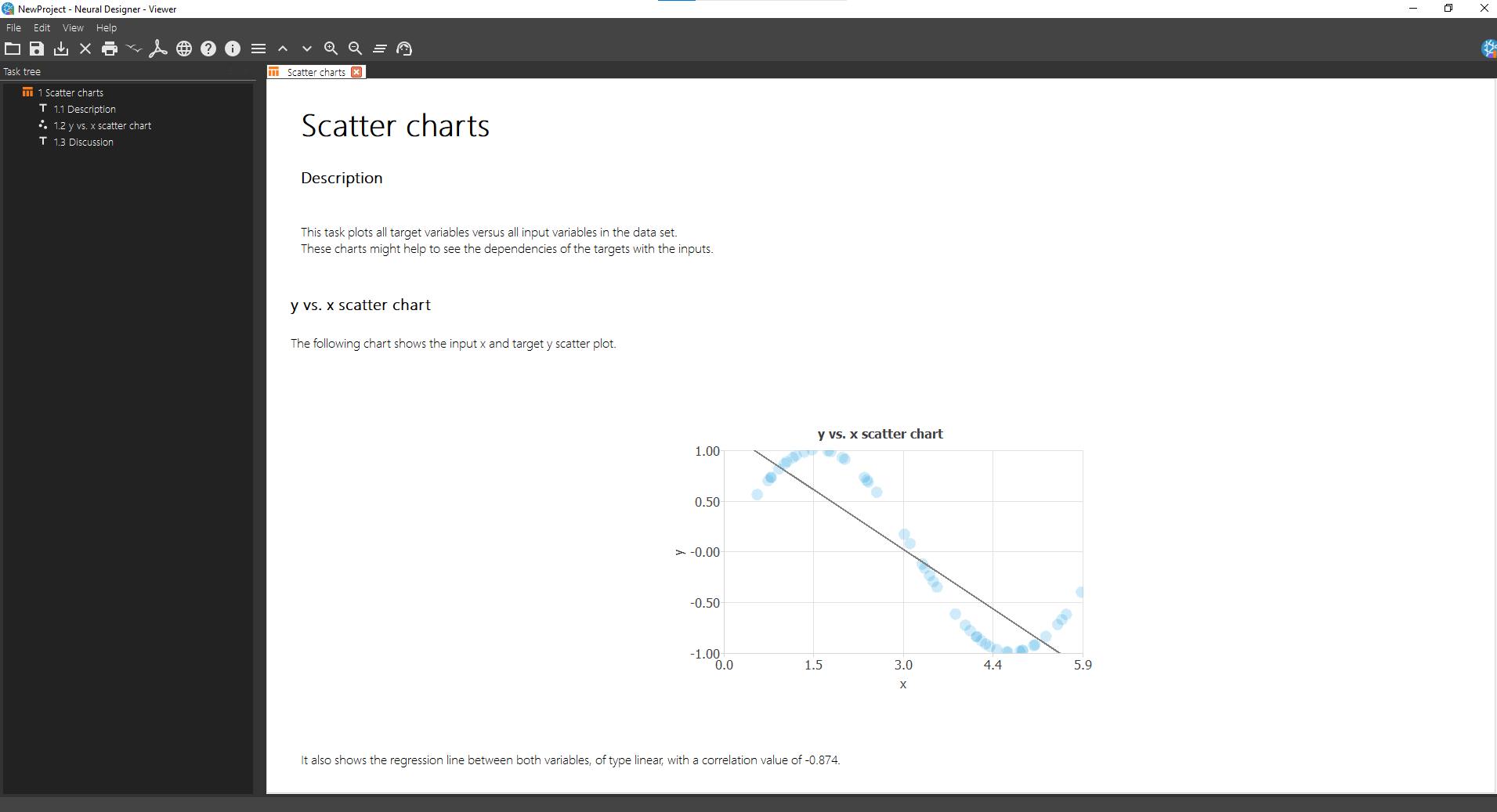
You can also evaluate data quality by running additional dataset analysis tasks.
3. Set network architecture
Next, click on the Neural network tab to configure the approximation model. The next screenshot shows this page.
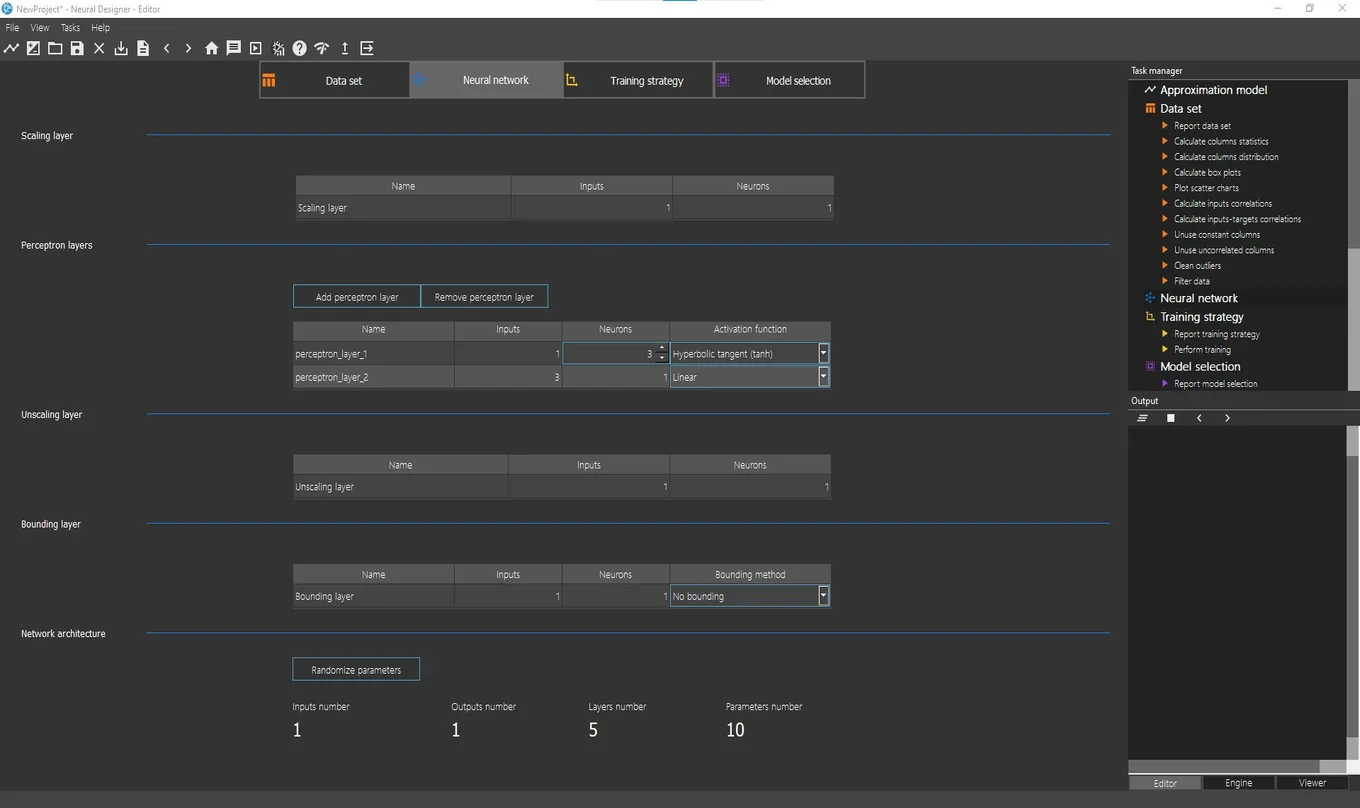
Focus on the Perceptron layers section. By default, the network contains two layers: one hidden layer and one output layer.
The hidden layer includes 3 neurons with a hyperbolic tangent activation function.
Since the model has one target (y), the output layer includes 1 neuron.
The output layer uses a linear activation function.
Keep these default settings.
To visualize the network architecture, open Task manager > Neural network > Report neural network. The Viewer window displays a graphical representation of the network.
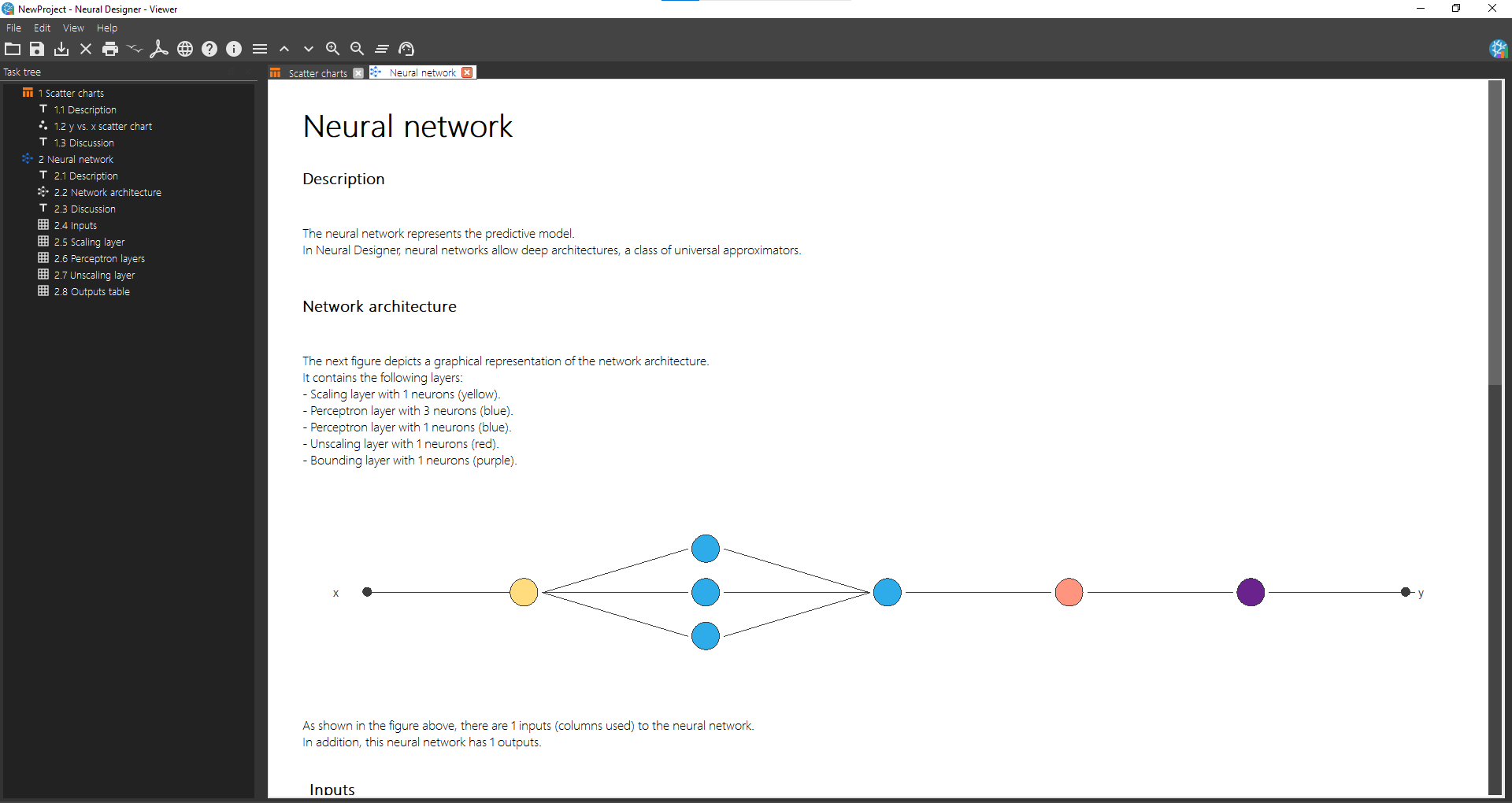
4. Train neural network
Next, open the Training strategy page. Here you configure the error method and optimization algorithm.
The next figure shows this page.
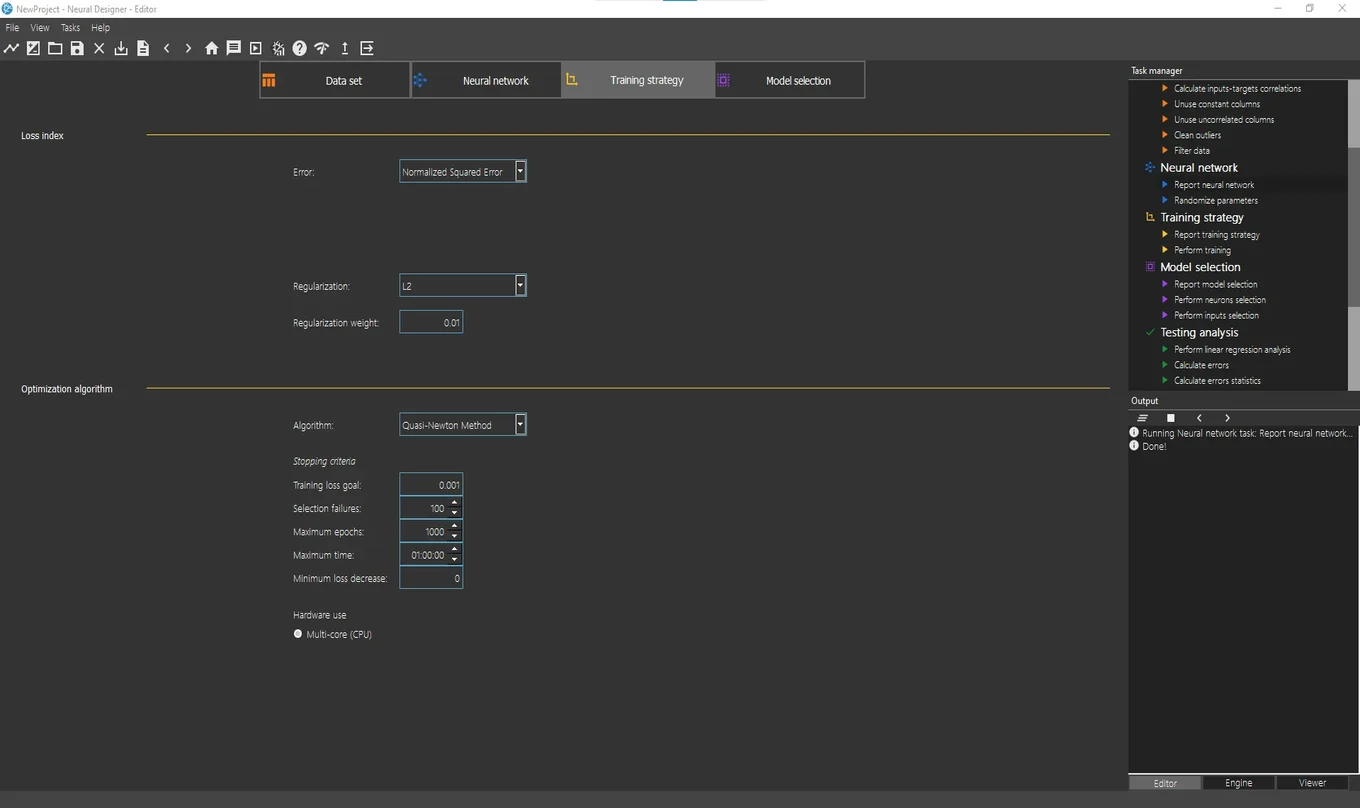
The normalized squared error is the default error method. A regularization term is also added here. The quasi-Newton method is the default optimization algorithm. We leave that default values.
The most important task is the so-called Perform training, which appears in the Task manager’s list of Training strategy tasks.
Running that task, the optimization algorithm minimizes the loss index, i.e., makes the neural network fit the data set.
The following figure shows the results from the Perform training task in the Viewer window.
The figure above shows the training results. It displays how both the training (blue) and selection (orange) errors decrease during the training process.
5. Improve generalization performance
The model selection tab shows the options that allow configuring the model selection process. The next image shows the content of this page.
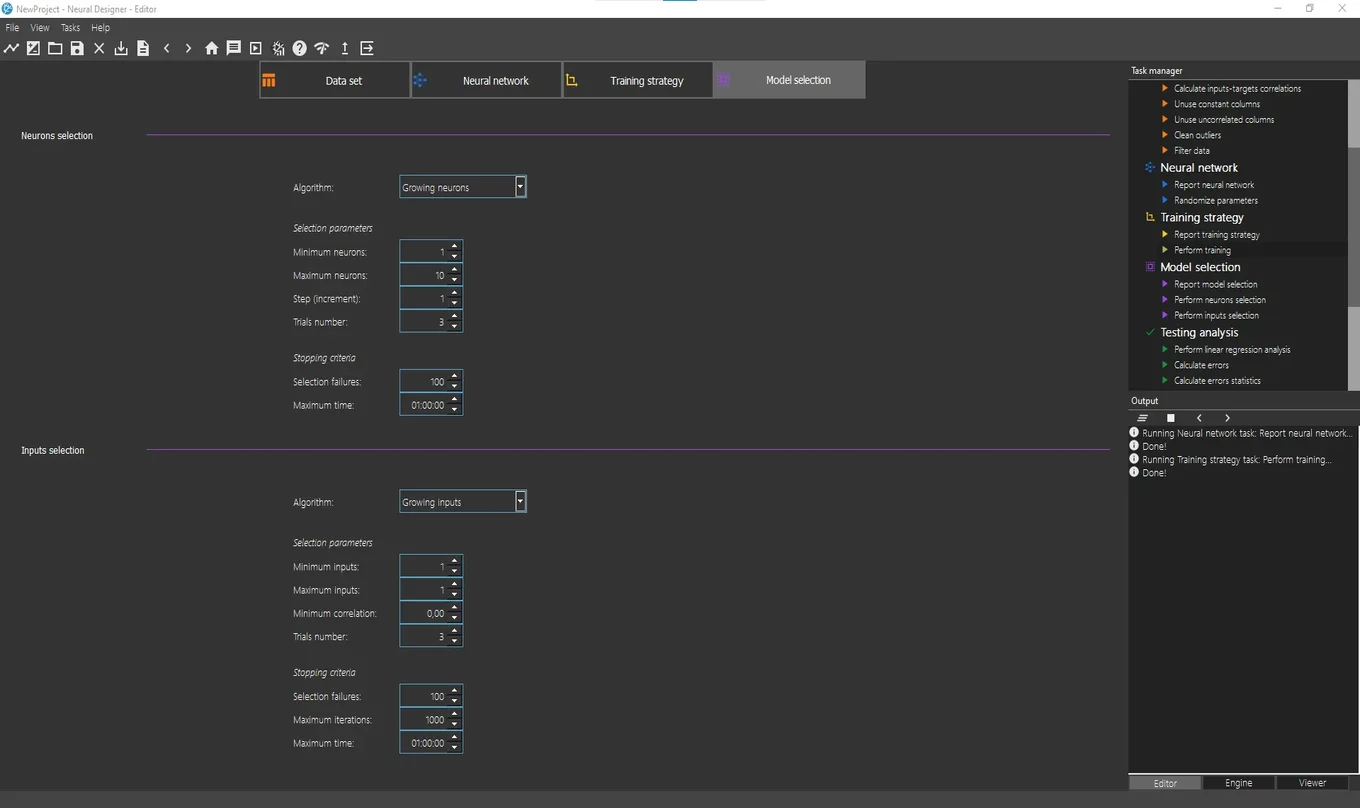
Growing neurons and growing inputs are the default options for Neurons selection and Inputs selection, respectively.
Since we will use the four inputs, Input selection will not be needed. To perform the Neurons selection, double click on Task manager> Model selection> Neurons Selection . The figure below shows the Viewer windows with the results of this task.
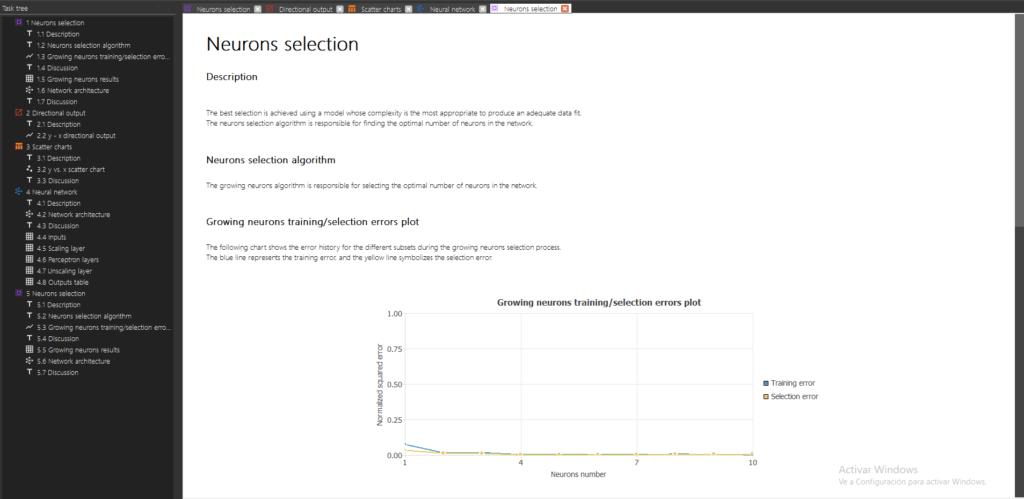
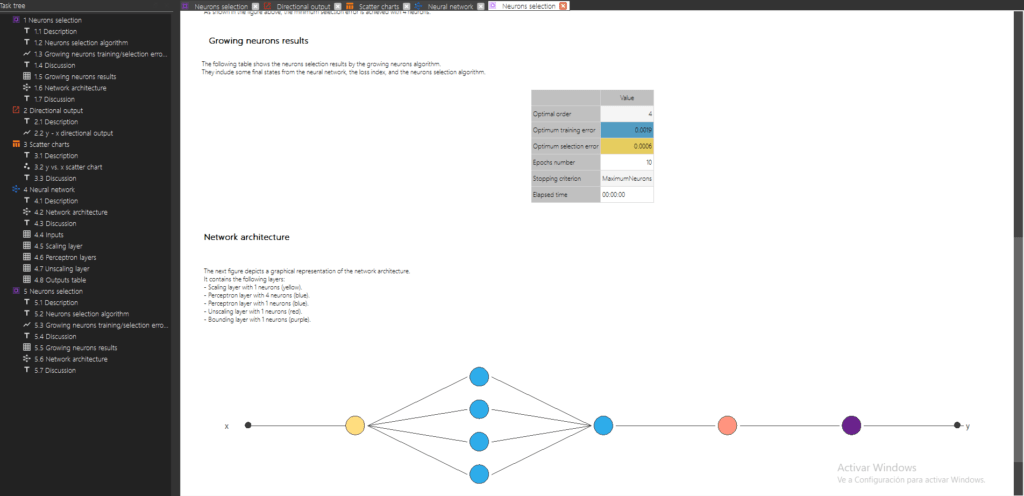
As we can see, an optimal network architecture has been defined after performing the Neurons selection task. This redefined neural network is already trained.
6. Test results
There are several tasks to test the model that has been previously trained. These tasks are grouped under Testing analysis in the Task manager.
To test this model, double click on Task manager> Testing analysis> Perform goodness-of-fit analysis The next figure shows the results of this task.
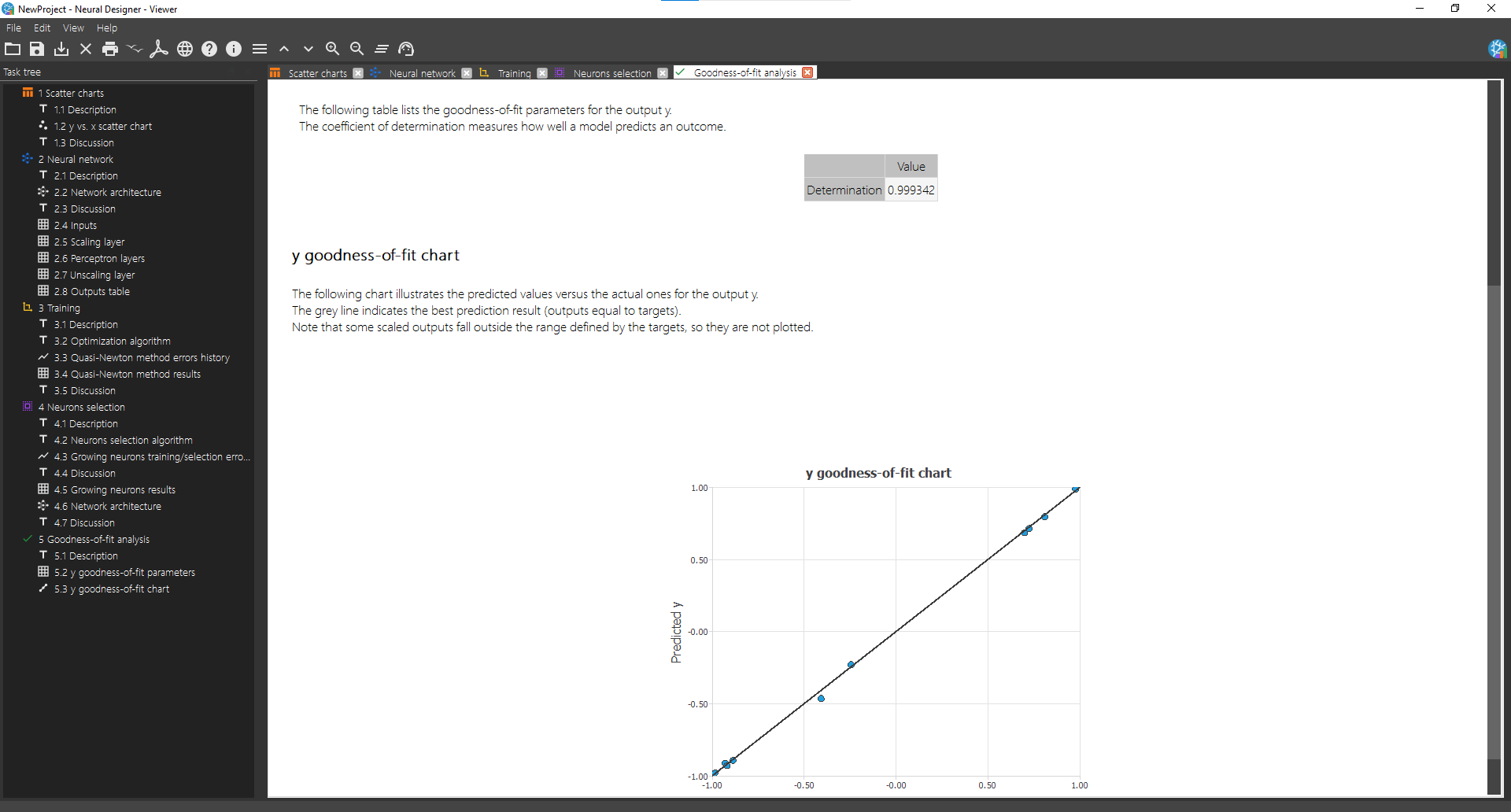
As we can observe in the table shown in the Viewer, the correlation is very close to 1, so we can say the model predicts well.
7. Deploy model
Once you have tested the model, it is ready to make predictions. The Model deployment menu from the Task manager contains the tasks for this purpose.
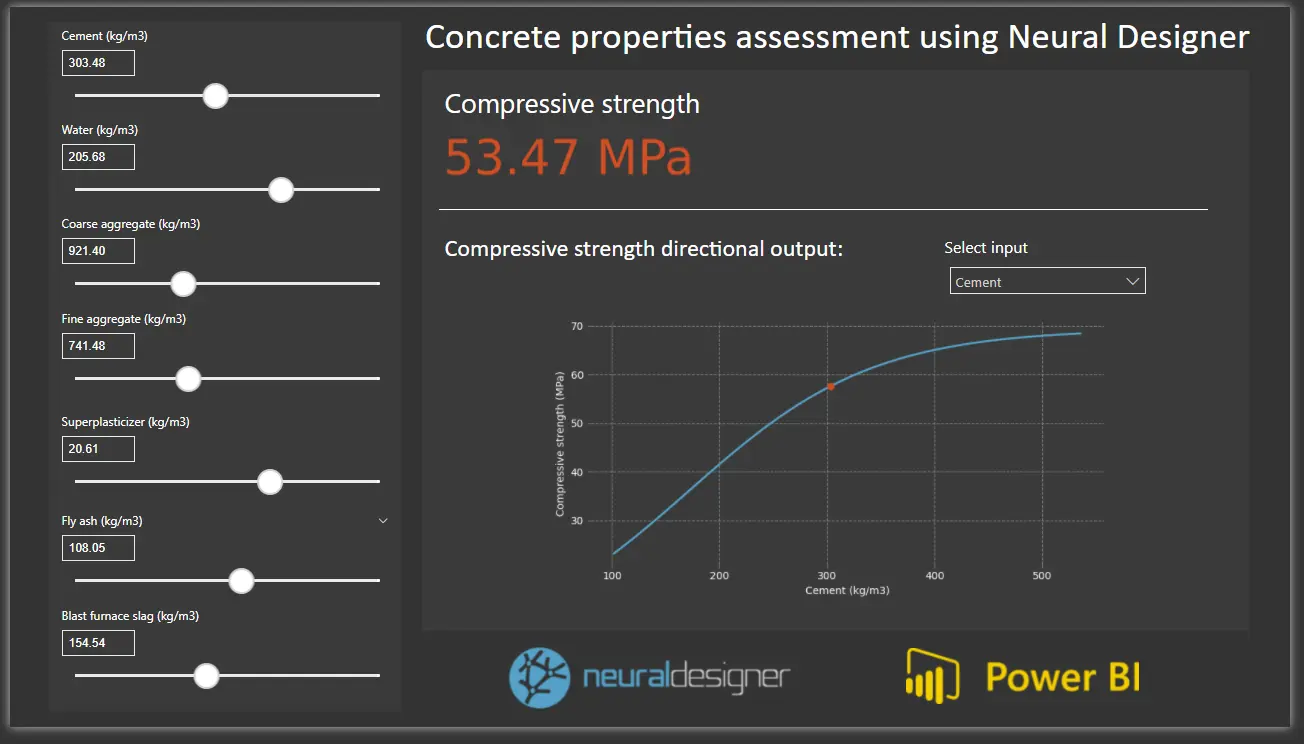
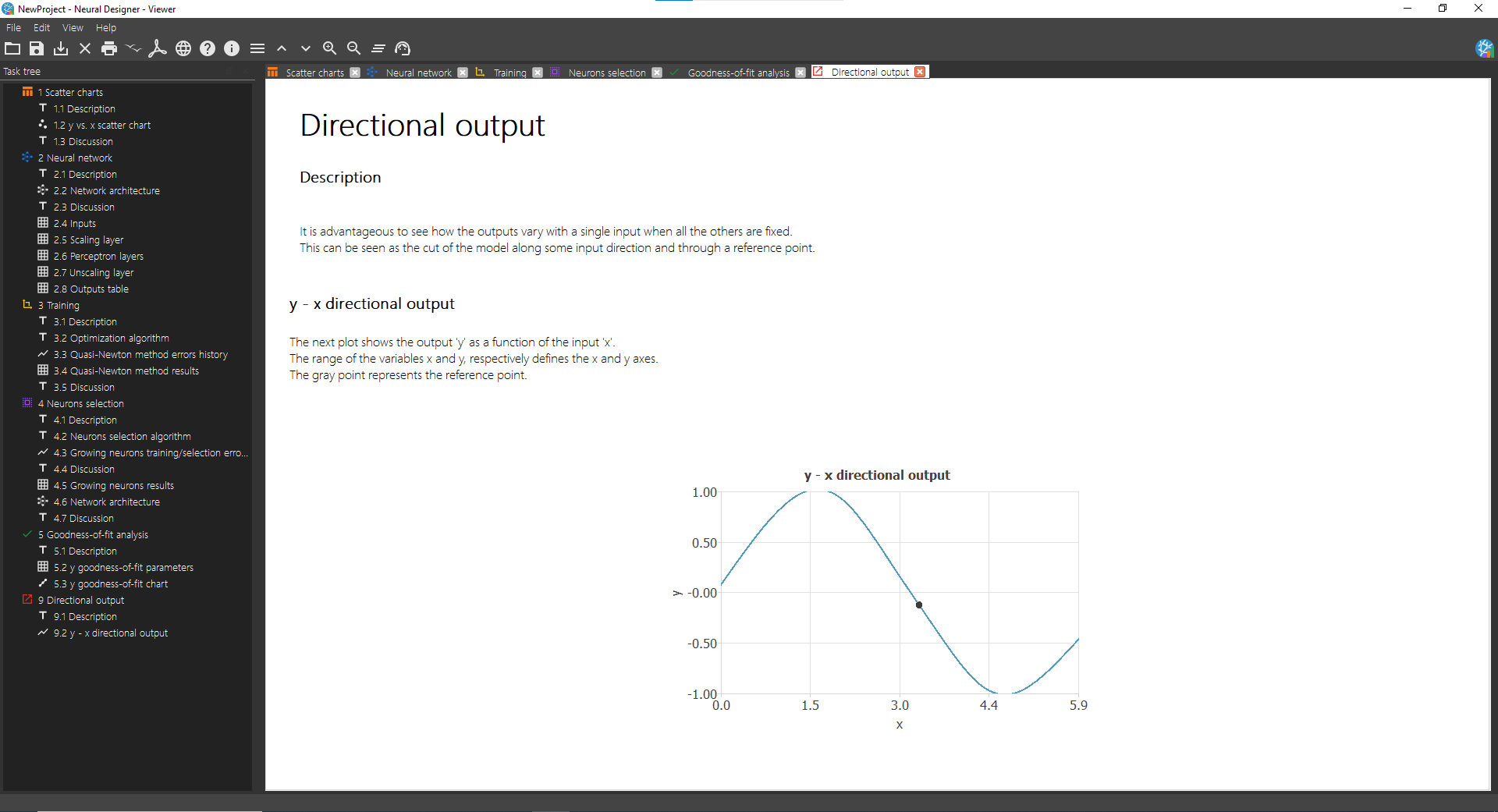
Double click on Task manager> Model deployment> Plot directional output to see the output variation as a function of a single input. The picture below shows the results after performing this task.
Model deployment tasks also include the option of writing the expression of the predictive model, in addition to exporting this expression to Python or C. The Python code corresponding to this model is presented below.
import numpy as np def scaling_layer(inputs): outputs = [None] * 1 outputs[0] = inputs[0]*0.3183101416+0 return outputs; def perceptron_layer_0(inputs): combinations = [None] * 3 combinations[0] = 0.0544993 +1.84365*inputs[0] combinations[1] = -1.40552 -1.52111*inputs[0] combinations[2] = 1.47629 -1.67521*inputs[0] activations = [None] * 3 activations[0] = np.tanh(combinations[0]) activations[1] = np.tanh(combinations[1]) activations[2] = np.tanh(combinations[2]) return activations; def perceptron_layer_1(inputs): combinations = [None] * 1 combinations[0] = -0.094707 +1.89925*inputs[0] +1.47562*inputs[1] +1.54961*inputs[2] activations = [None] * 1 activations[0] = combinations[0] return activations; def unscaling_layer(inputs): outputs = [None] * 1 outputs[0] = inputs[0]*1.270824432+0.2996354103 return outputs def bounding_layer(inputs): outputs = [None] * 1 outputs[0] = inputs[0] return outputs def neural_network(inputs): outputs = [None] * len(inputs) outputs = scaling_layer(inputs) outputs = perceptron_layer_0(outputs) outputs = perceptron_layer_1(outputs) outputs = unscaling_layer(outputs) outputs = bounding_layer(outputs) return outputs;
To learn more, see the next example: