1. Export the model to Python
After training our approximation model as seen in the Build a Neural Network in 7 steps tutorial, we will proceed to export that model to Python. You will find the task at the bottom of the Task manager, under the Model deployment section.
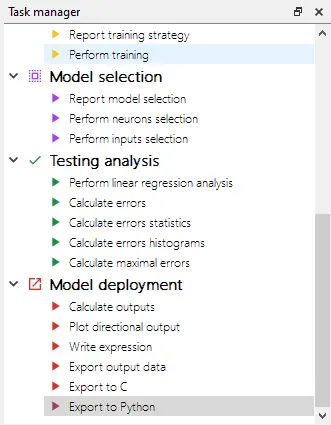
This option will allow you to save a .py file with your training model ready for use.
If you open this file in your Python editor, you will find some documentation on using it on top.
Once we have this code, we can open Power BI to make the deployment.
2. Integrate the model in Power BI
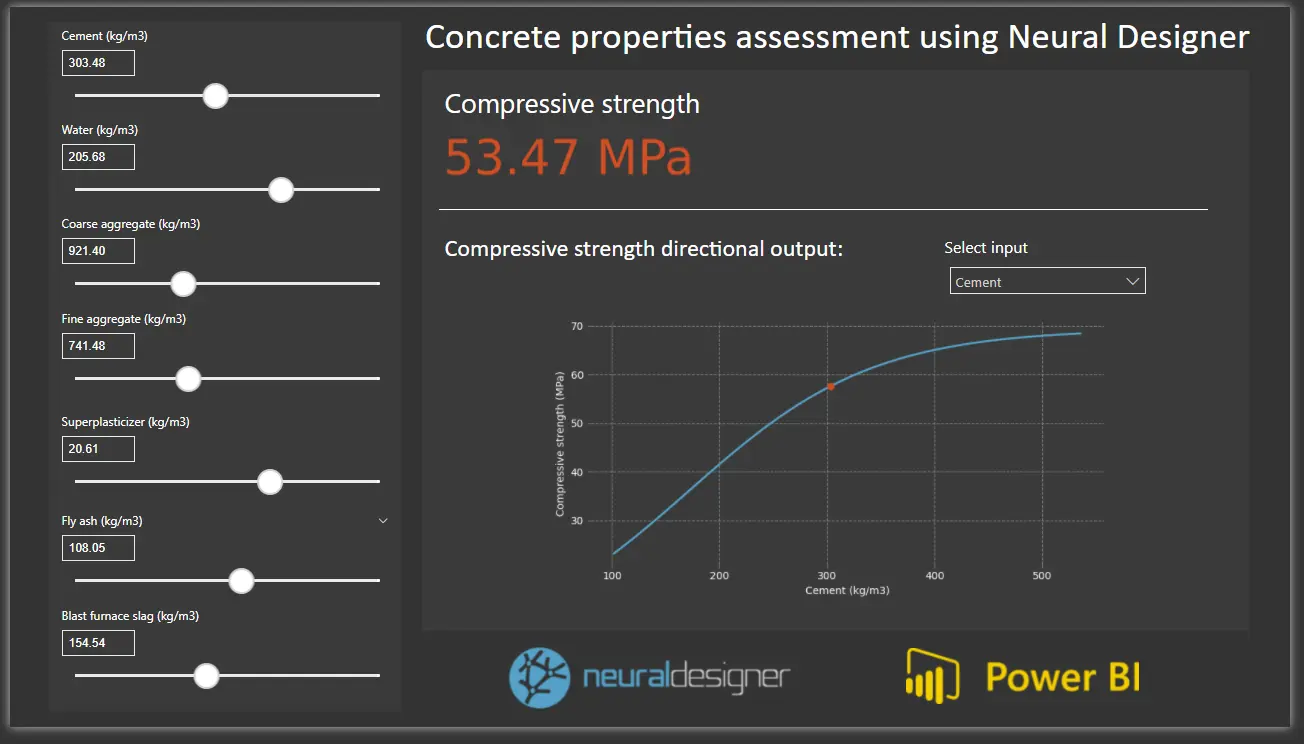
In this case, we will be implementing a Power BI report that shows the output calculated by the model for a series of input values and the directional outputs given for those same values.
We will be working with variables’ parameters, so there is no need to load any dataset. To get the values of those parameters from the user, we will create a slider for each of the input variables.
Create input sliders with parameters
We will click on New Parameter on the modeling tab to create these sliders. There we will use the range of the variable and, as step, the value that gives us 100 steps for such range.
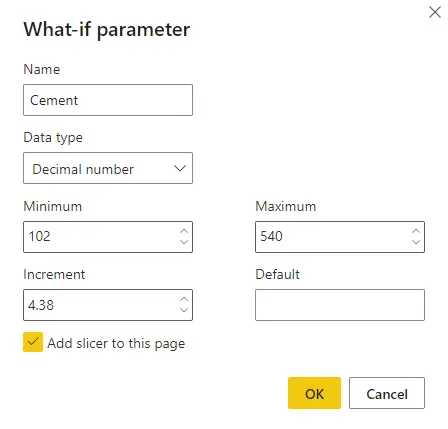
Once we create the sliders for all the inputs, we stack them for easier access.
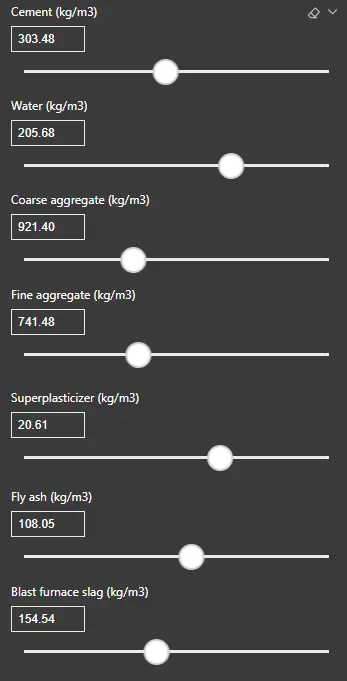
We will name the parameter fields as follows to later work with them in Python.
Show the model output with a Python visual
To calculate the target value, we will be using the Python visual functionality, which allows us to embed a Python script in Power BI. We use the code exported by Neural Designer to calculate the output and, then we plot it so that it can be seen on our report.
The code added to the model is
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.patheffects as path_effects
model = NeuralNetwork()
# Parameter point
input_parameters = [dataset.cement_parameter, dataset.blast_furnace_slag_parameter, dataset.fly_ash_parameter, dataset.water_parameter, dataset.superplasticizer_parameter, dataset.coarse_aggregate_parameter, dataset.fine_aggregate_parameter]
output_point = round(model.calculate_output(input_parameters)[0][0],2)
fig = plt.figure(figsize=(60, 10))
fig.patch.set_facecolor('#3A3A3A')
text = fig.text(0, 0.5, str(output_point) + ' MPa',
ha='left', va='center', size=500, color ='#d04f25')
text.set_path_effects([path_effects.Normal()])
plt.show()
This way, after adding a text box with the name of the target variable, we get the Neural Network’s output.

Create directional output plots with a dropdown selector
Next, we will create the directional outputs for each of the inputs. To save some space, we will use a dropdown menu to select the input the user wants to visualize.
First of all, we have to create a new data table with the names of the variables and the order we want them to appear in.
Then, we create a dropdown slicer by clicking on the slicer icon in the visualization section and selecting the inputs column in the table we just created.
Now, we will add another python visual to create the directional output plots. We will use all the inputs’ parameters and the dropdown slicer as values for this visual.
Just as we did while calculating the output, we paste the exported model and add some code to show the plots.
The code added to the model is the one that follows:
This will show us the directional output for the different input values selected in the dropdown menu.
We can now try changing the parameter values and watch how the visualization of the target’s values changes with the inputs.
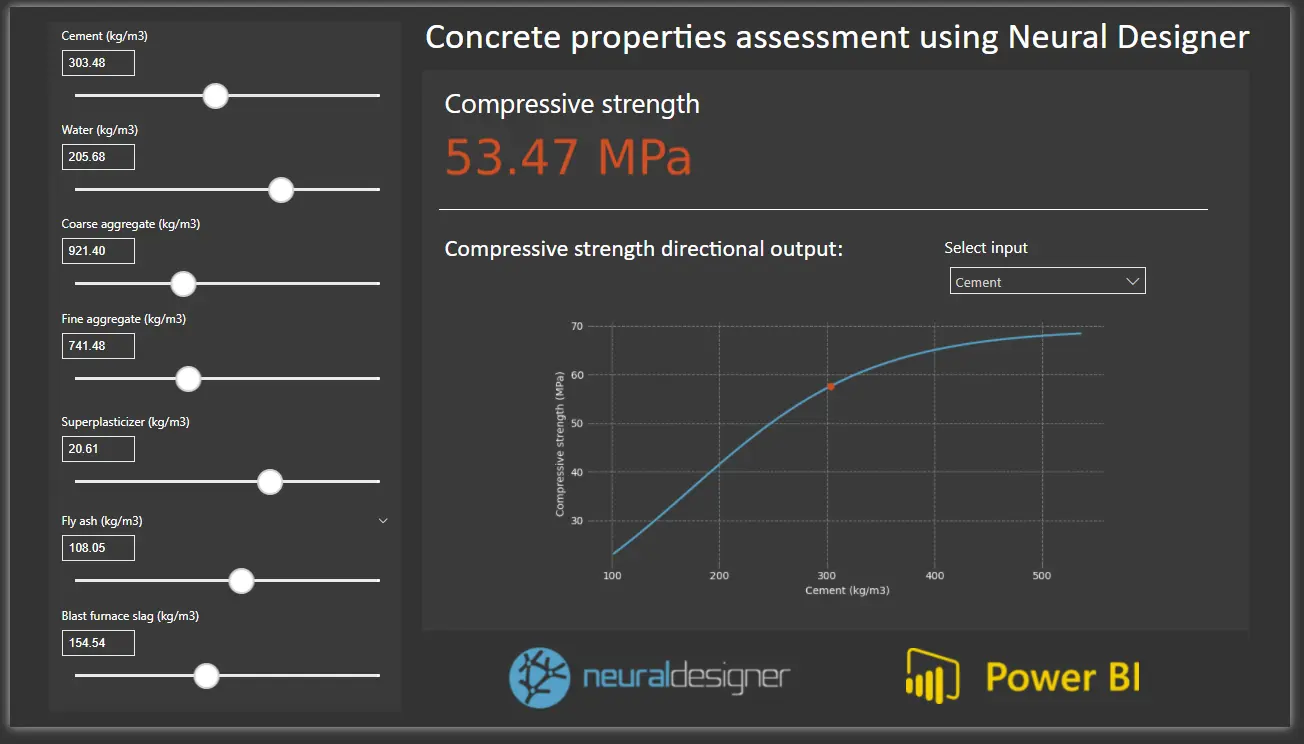
We can give the report the format we desire, and use it for a formal presentation or as a powerful Bussiness Intelligence tool.
To learn more, see the next example: