Develop an e-nose to detect alcohols using machine learning
This example builds a machine learning model to develop an e-nose to detect alcohols.
Scientists design electronic noses to mimic humans’ sensory abilities for detecting complex mixtures of chemical substances and biological origin. A QCM is an electromechanical oscillator containing a thin slice of quartz crystal with two channels on its surface. This physical device is sensitive to the resonance frequency. The central goal here is to design an electronic nose model that makes proper classifications for different alcohol types (1-Octanol, 1-propanol, 2-butanol, 2-propanol, 1-Isobutanol) using QCM sensor data.
This is a classification project since the variable to be predicted is categorical (1-Octanol, 1-propanol, 2-butanol, 2-propanol, 1-Isobutanol).
2. Data set
The first step is to prepare the data set, which is the source of information for the classification problem.
For that, we need to configure the following concepts:
Data source.
Variables.
Instances.
The data source is the file QCMalcoholsensor.csv. It contains the data for this example in comma-separated values (CSV) format. The number of columns is 6, and the number of rows is 26. The variables are:
freq_1: Measured frequency for concentration 1: Air ratio (ml): 0.799 Gas ratio(ml):0.201
freq_2: Measured frequency for concentration 2: Air ratio (ml): 0.700 Gas ratio(ml):0.300
freq_3: Measured frequency for concentration 3: Air ratio (ml): 0.600 Gas ratio(ml):0.400
freq_4: Measured frequency for concentration 4: Air ratio (ml): 0.501 Gas ratio(ml):0.499
freq_5: Measured frequency for concentration 5: Air ratio (ml): 0.400 Gas ratio(ml):0.600
class: 1-Octanol, 1-Propanol, 2-Butanol, 2-Propanol, 1-Isobutanol used as the target.
The input variables are the first five variables. The sensor processes each alcohol through five different concentrations.
Note that neural networks work with numbers. In this regard, we transform the categorical variable “class” into five numerical variables as follows:
1-Octanol: 1 0 0 0 0.
1-Propanol: 0 1 0 0 0.
2-Butanol: 0 0 1 0 0.
2-Propanol: 0 0 0 1 0.
1-Isobutanol: 0 0 0 0 1.
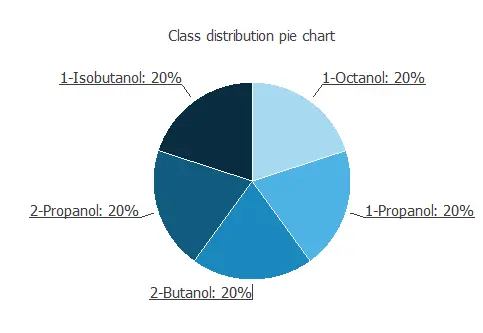
The instances are divided into training, selection, and testing subsets. They represent 60% (15), 0% (0), and 20% (25) of the original instances, respectively, and are split at random. We can calculate the distributions of all variables. The next figure is the pie chart for the alcohol types.
As we can see, the target is well-distributed since there is the same number for the five different alcohol types.
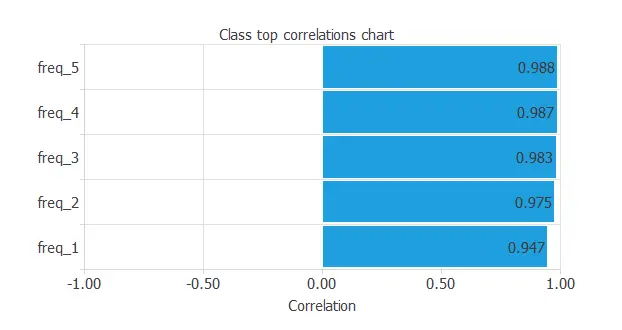
We observe a strong correlation among the variables.
3. Neural network
The second step is to choose a neural network. In classification problems, one typically composes:
A scaling layer.
Two perceptron layers.
A probabilistic layer.
The scaling layer contains the statistics on the inputs calculated from the data file and the method for scaling the input variables.
Here, we have set the minimum and maximum methods. Nevertheless, the mean and standard deviation method would produce very similar results. In our case, there is no perceptron layer. This is due to having little data, so we simplify the program. The probabilistic layer allows the outputs to be interpreted as probabilities. In this regard, all outputs are between 0 and 1, and their sum is 1.
The softmax probabilistic method is used here. The neural network has five outputs since the target variable contains 5 classes (1-Octanol, 1-propanol, 2-butanol, 2-propanol, 1-Isobutanol).
4. Training strategy
The fourth step is to establish the training strategy, which comprises:
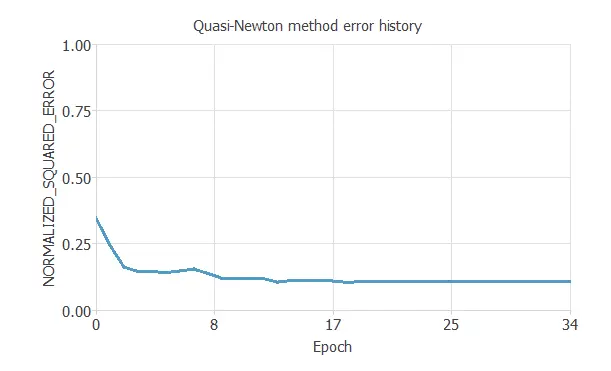
The following chart shows how training and selection errors decrease with the epochs during training.
The final value is training error = 0.109 NSE, and the selection error doesn’t appear because we divided the instances into training and testing subsets.
5. Model selection
The objective of model selection is to find the network architecture with the best generalization properties, which minimizes the error on the selected instances of the data set.
Order selection algorithms train several network architectures with a different number of neurons and select that with the smallest selection error.
The incremental order method starts with a few neurons and increases the complexity at each iteration.
6. Testing analysis
The purpose of the testing analysis is to validate the generalization performance of the model.
Here, we compare the neural network outputs to the corresponding targets in the testing instances of the data set.
In the confusion matrix, the rows represent the targets (or real values), and the columns represent the corresponding outputs (or predictive values).
The diagonal cells show the correctly classified cases, and the off-diagonal cells show the misclassified cases.
Predicted 1-Octanol
Predicted 1-Propanol
Predicted 2-Butanol
Predicted 2-Propanol
Predicted 1-Isobutanol
Real 1-Octanol
1 (10.0%)
0
0
0
0
Real 1-Propanol
0
3 (30.0%)
0
0
0
Real 2-Butanol
0
0
3 (30.0%)
0
0
Real 2-Propanol
0
0
0
1 (10.0%)
0
Real 1-Isobutanol
0
0
0
0
2 (20.0%)
As we can see, the number of instances the model can correctly predict is 10 (100%), so there are no misclassified cases.
This shows that our predictive model has excellent classification accuracy.
7. Model deployment
The neural network is now ready to predict outputs for inputs it has never seen.
This process is called model deployment. To classify a given alcohol, we calculate the neural network outputs from the frequencies corresponding to the different types of concentration.
For instance:
Freq_1: -54.764 Hz.
Freq_2: -90.826 Hz.
Freq_3: -132.372 Hz.
Freq_4: -173.337 Hz.
Freq_5: -220.833 Hz.
Probability of 1-Octanol: 1.5 %.
Probability of 1-Propanol: 9.6 %.
Probability of 2-Butanol: 1.3 %.
Probability of 2-Propanol: 24.2 %.
Probability of 1-Isobutanol: 63.4 %.
For this particular case, our e-nose developed would classify the alcohol as 1-Isobutanol since it has the highest probability.
M. Fatih Adak, Peter Lieberzeit, Purim Jarujamrus, Nejat Yumusak, Classification of alcohols obtained by QCM sensors with different characteristics using ABC based neural network, Engineering Science and Technology, an International Journal, 2019, ISSN 2215-0986.Web Link.