In this example, we build a machine learning model to forecast the oil production from the field for the following days or weeks.
For that, we examine Equino’s published production data from the Volve field in Norway.
Analysis of oil well production data is crucial for maximizing production and identifying potential issues.
Contents
- Application type.
- Data set.
- Neural network.
- Training strategy.
- Model selection.
- Testing analysis.
- Model deployment.
This example is solved with Neural Designer. To follow it step by step, you can use the free trial.
Volve is an oil field in the Norwegian North Sea near Stavanger. Equinor and its partners have published all field data online for research and development purposes. Volve, discovered in 1993, extracted oil and gas between 2008 and 2016. The implementation of water injection sustained pressure, effectively doubling the field’s lifespan beyond its initial expectations.
A lot of data is available for analysis. In this example, we focus on well 5351, which produced more than 40% of the total oil production from the field.
1. Application type
This forecasting project aims to predict the value of oil production rates in the coming days using artificial intelligence and machine learning techniques.
The objective is to obtain an accurate prediction based on available data and utilize these predictions to enhance production processes and identify potential issues.
2. Data set
Data source
The volve_field_data.csv file contains 2959 samples, each with 7 input features collected from 2008 to 2016. The dataset is transformed into a time series, incorporating lagged values and forward steps, which serves the purpose of forecasting.
Variables
The following list summarizes the variable’s information:
Downhole conditions
- down_hole_pressure – Fluid pressure at the bottom of the wellbore (bar).
- down_hole_temperature – Average fluid temperature at the bottom of the wellbore (°C).
Wellhead conditions
- well_head_pressure – Fluid pressure at the top of the wellbore (bar).
- well_head_temperature – Fluid temperature at the top of the wellbore (°C).
Flow control parameters
- production_pipe_pressure – Pressure difference between two points in the production pipeline (bar).
- choke_size_pct – Choke valve opening percentage, used to control fluid flow.
- choke_size_pressure – Pressure difference across the choke valve (bar).
Target variable
- oil – Daily oil production volume, measured in cubic meters (m³/day).
Instances
The dataset is split into training, validation, and testing subsets, with 60% of the instances assigned for training, 20% for validation, and 20% for testing, as specified by Neural Designer. The user can change these values as desired.
Once the data set has been set, we are ready to perform a few related analytics. With that, we verify the provided information and ensure the data is of high quality.
Variables statistics
We can calculate the data statistics and create a table that displays the minimums, maximums, means, and standard deviations of all variables in the dataset. The following table displays the values.
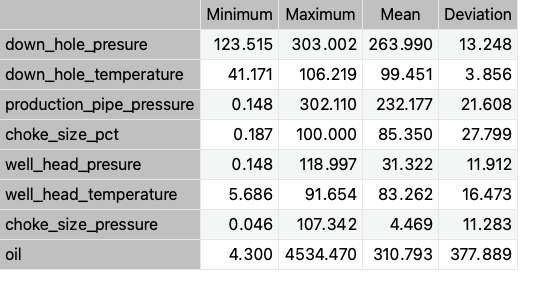
We observed a significant deviation in oil production. The multiple production-related wellbore shutdowns may be a contributing factor.
Inputs-targets correlations
Additionally, we can obtain the existing correlations between inputs and targets for each variable, which allows us to understand the importance of the different influences on oil production.
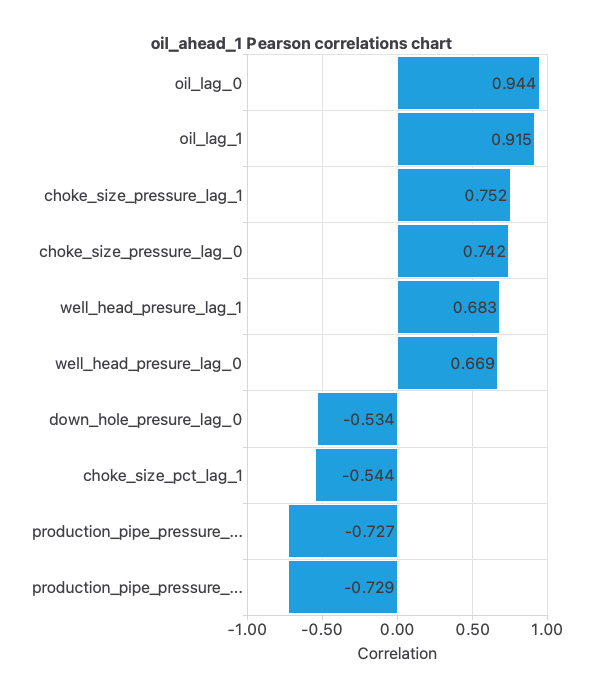
For example, we can observe a strong and negative correlation between oil production and pipe production pressure, indicating that as one increases, the other decreases.
The negative correlation between oil production and pipeline pressure is logical, as a decrease indicates more efficient oil flow and higher production. An increase in pressure signals production issues and lower production.
3. Neural network
The next step is to set up a neural network that represents the approximation function. In this class of applications, the neural network comprises:
The scaling layer contains the statistics on the inputs calculated from the data file and the method for scaling the input variables. Here, the minimum-maximum method has been set. As we use 16 input variables, the scaling layer has 16 inputs.
We use 2 perceptron layers here:
- The first perceptron layer has 16 inputs, 3 neurons, and a hyperbolic tangent activation function
- The second perceptron layer has 3 inputs, 1 neuron, and a linear activation function
The unscaling layer contains the statistics of the output.
The following figure is a graphical representation of this neural network.
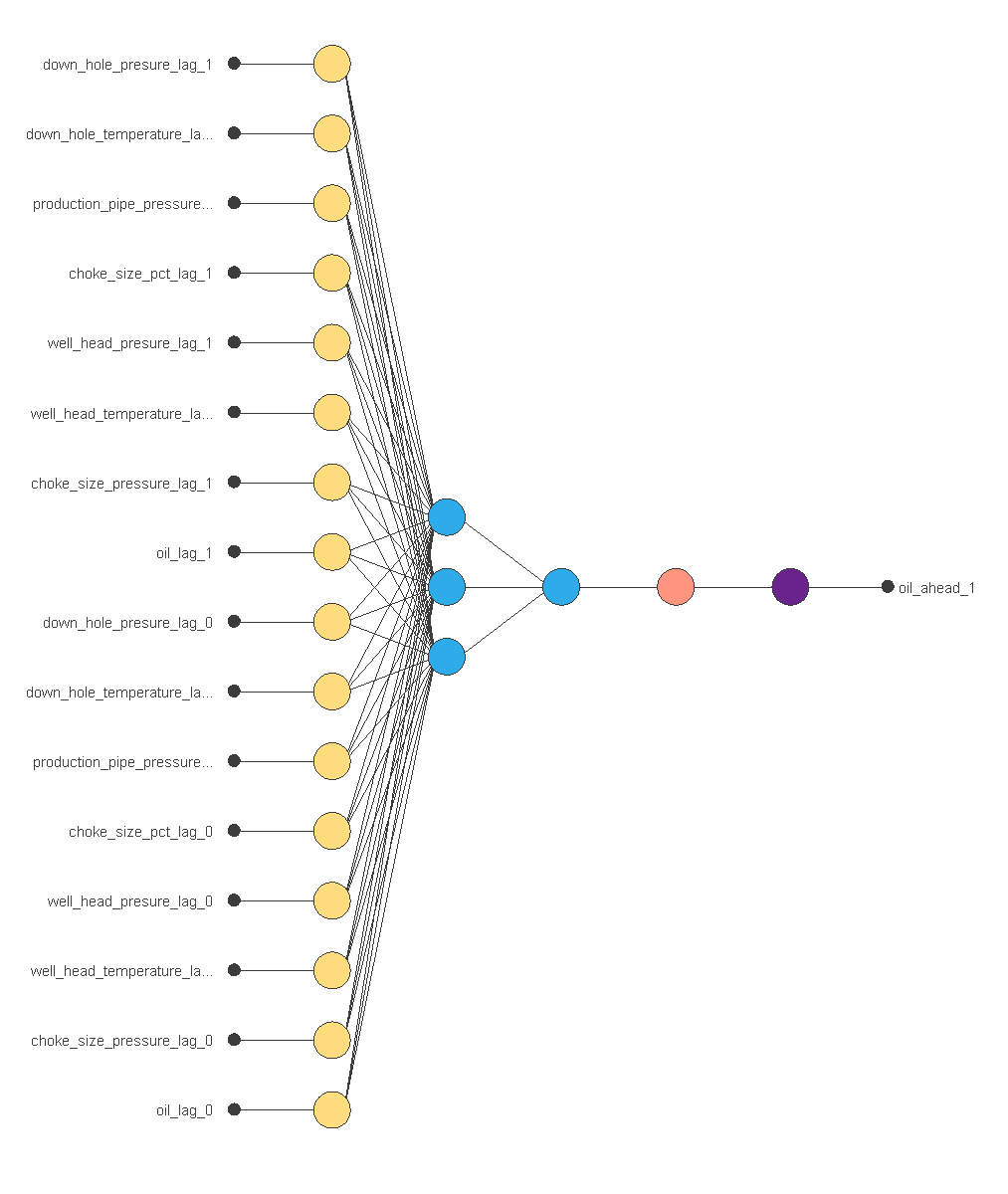
4. Training strategy
A training strategy is employed to facilitate the learning process. Then, we apply the training strategy to the neural network to optimize its performance. How the parameters adjust in the neural network determines the type of training.
We set the weighted squared error with L2 regularization as the loss index.
On the other hand, we use the quasi-Newton method as the optimization algorithm.
The following chart illustrates how the training (blue) and selection (orange) errors decrease with the epochs of the quasi-Newton method during the training process.
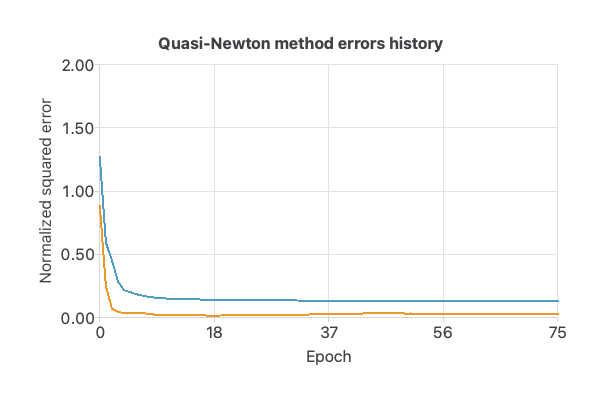
The final values are training error = 0.125 ME and selection error = 0.027 ME.
That indicates that the neural network has good generalization capabilities.
5. Model selection
The objective of model selection is to find the network architecture with the best generalization properties, which minimizes the error on the selected instances of the data set.
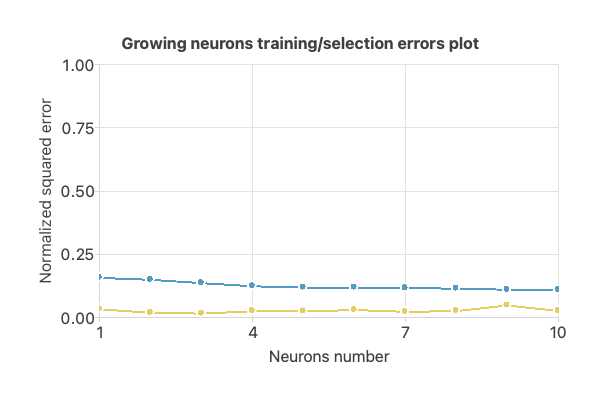
Order selection algorithms train several network architectures with different numbers of neurons and select the one with the smallest selection error.
The incremental order method begins with a small number of neurons and gradually increases their complexity at each iteration.
The following chart shows the training error (blue) and the selection error (yellow) as a function of the number of neurons.
6. Testing analysis
Once you have trained the model, you can perform a testing analysis to validate its prediction capacity. We use a subset of data that has not been used before, the testing instances.
To verify the results obtained in this example, the graphs comparing the actual oil production values are shown below.
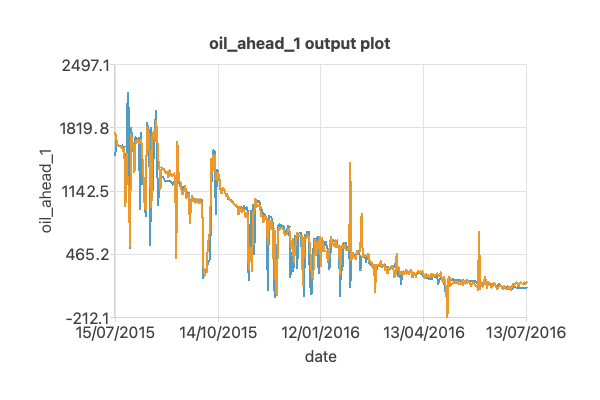
The oil precision graph shows a good match between the prediction and actual results, leading to satisfactory outcomes.
On the other hand, the following table presents the relative error obtained using the previous value as a prediction (base model) and the neural network model.
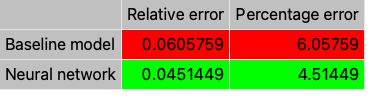
As we can see, this comparison demonstrates the effectiveness of the neural network model versus the baseline prediction technique.
7. Model deployment
The neural network is now ready to predict the activity of new people in the so-called model deployment phase.
The file volve-field-forecasting.py implements the mathematical expression of the neural network in Python. You can embed this piece of software in any tool to make predictions on new data.
References
- We have taken the data for this problem from the Volve field data set.



