This tutorial describes different machine learning model types.
Neural networks use information in the form of data to generate knowledge in the form of models.
A model can be defined as a description of a real-world system or process using mathematical concepts.
It is usually represented as a mapping between input and output variables.
In this regard, neural networks are used to discover relationships, recognize patterns, predict trends, and recognize associations from data.

Model types
- 1.1. Approximation (or function regression)
- 1.2. Classification (or pattern recognition)
- 1.3. Forecasting (or time series prediction)
- 1.4. Auto association
- 1.5. Text classification
- 1.6. Image classification model
1.1. Approximation (or function regression)
An approximation can be regarded as the problem of fitting a function to a set of data.
Here, the neural network learns from knowledge represented by a data set consisting of instances with input and target variables. The targets are a specification of the response to the inputs.
In this regard, the primary goal of an approximation problem is to model one or several target variables conditioned on the input variables.
The objective here is to estimate the value of y, knowing the value of x. The following figure illustrates an approximation problem.
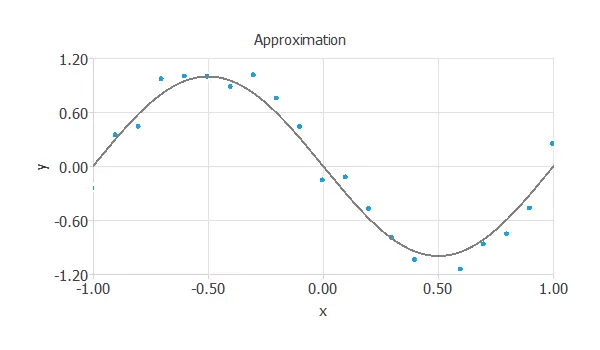
In approximation applications, the targets are usually continuous variables.
Some examples are the following:
- Model the strength of high-performance concretes.
- Predict the noise generated by airfoil blades.
- Predict the residuary resistance of sailing yachts.
- Predict the vascular adhesion of nanoparticles.
- Predict the electricity generated by combined cycle power plants.
- Forecast the power generated by a solar plant.
- Model wine preferences from physicochemical properties.
A common feature of most data sets is that the data exhibits an underlying systematic aspect, represented by some function, but is corrupted with random noise.
The objective is to produce a neural network that exhibits good generalization, or in other words, one that makes good predictions for new data.
The best generalization is obtained when the mapping represents the underlying systematic aspects of the data rather than capturing the specific details (i.e., the noise contribution).
1.2. Classification (or pattern recognition)
Classification can be stated as the process whereby a received pattern, characterized by a distinct set of features, is assigned to one of a prescribed number of classes.
The inputs here include features that characterize a pattern, while the targets specify the class of each pattern.
The primary goal in a classification problem is to model the posterior probabilities of class membership, conditioned on the input variables.
The following figure illustrates a classification task. Here, we want to discriminate the class (circles or green squares) based on the x1 and x2 values of the object.
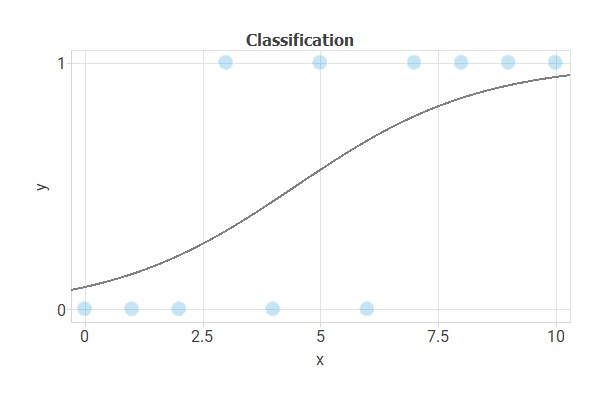
As before, the central goal is to design a neural network with good generalization capabilities. That is a model that can accurately classify new data.
We can distinguish between two types of classification models:
Binary classification
In binary classification, the target variable is usually binary (true or false).
Some examples are to:
- Diagnose breast cancer from fine-needle aspirate images.
- Detect forged banknotes.
- Reduce employee attrition.
- Increase the conversion rate of telemarketing campaigns in banks.
- Predict the probability of default of credit card clients.
- Detect diseased trees from remote sensing data.
- Target donors in blood donation campaigns.
- Diagnose acute inflammations of the urinary bladder.
- Predict customer churn in telecommunications companies.
Multiple classification
In multiple classifications, the target variable is usually nominal (class_1, class_2, or class_3).
Some examples are the following:

1.3. Forecasting (or time series prediction)
Forecasting can be regarded as the problem of predicting the future state of a system from a set of past observations to that system.
A forecasting application can also be solved by approximating a function from a data set. In this type of problem, the data is arranged in a time series fashion. The inputs include data from past observations (predictors), and the targets include corresponding future observations (predictands).
The primary goal here is to model future observations given past observations.
The following figure illustrates a forecast application. The objective is to predict the next step, yt+1, based on the lags yt, yt-1, and so on.
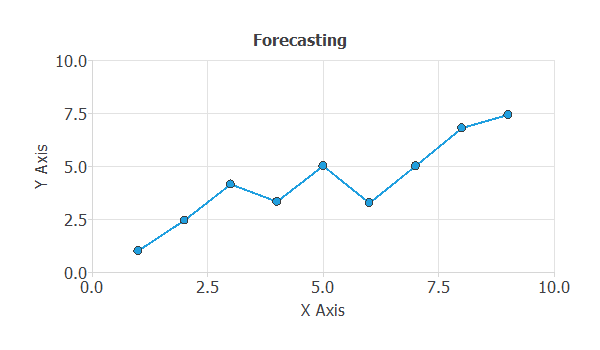
An example is forecasting future sales of a car model as a function of past sales, marketing actions, and macroeconomic variables.
As always, good generalization is the central goal in forecasting applications.

1.4. Auto association
Auto-association models are those in which we use auto-associative neural networks to learn a compressed or reduced representation of the input data.
The following figure illustrates an auto-associative neural network:
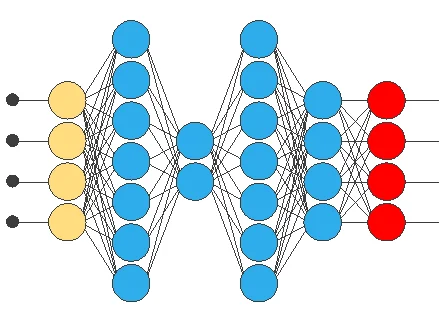
Auto-association models are beneficial for unsupervised learning tasks, where the goal is to learn underlying patterns in the data without needing labeled examples.
They can also be used for semi-supervised or supervised tasks where the model learns a representation of the normal data and then uses it to detect anomalies. Some examples of these uses are:
- Signal or failure detection: Detecting anomalies in sensor data, financial transactions, manufacturing processes, or medical vital signs by learning a representation of the normal data and using it to detect deviations.
- Recommender systems: Modeling user preferences and making recommendations.
- Denoising: Removing noise from images or other data by learning to reconstruct the original data from a noisy version.
In general, auto-association models are a powerful tool for various applications and have the potential to improve efficiency, simplify data complexity, and provide a deeper understanding of the underlying patterns in the data.
1.5. Text classification
Text classification is a natural language processing task in which text data is categorized into predefined labels or categories.
The basic goal of a text classification problem is to model one or several target variables conditioned on the input text data.
The objective here is to predict the category or label of a given text based on its content.
In text classification applications, the targets are usually discrete variables such as categories, labels, or sentiments.
Some examples are the following:
- Spam detection: Classifying emails as spam or not based on their content.
- Sentiment analysis: Classifying text data as positive, negative, or neutral based on the sentiment expressed.
- Topic classification: Classifying news articles into predefined topics such as politics, sports, technology, etc.
- Named entity recognition: Identifying and classifying named entities such as people, organizations, locations, etc.
A common feature of most text classification datasets is that text data exhibits an underlying systematic aspect, represented by specific patterns or features, but is also corrupted with random noise, such as typos, grammatical errors, or irrelevant information.
The objective is to produce a text classification model that exhibits good generalization, or in other words, one that makes good predictions for new text data.
1.6. Image classification model
Image classification is a computer vision task in which an entire image is assigned to one of a predefined set of classes. Unlike a conventional classification data set, every input sample is a three-dimensional tensor of pixel values with the shape height × width × channels. The model learns the visual features that distinguish one class from another directly from those pixels.
In Neural Designer, an image classification project combines an image data set with a convolutional neural network. Images are organized into one folder per class, and the folder names define the class labels. The data set must contain at least two non-empty class folders.
The image classification model processes the data through the following architecture:
- Image scaling: Pixel values are normalized with image min-max scaling.
- Feature extraction: One or more 3 × 3 convolutional layers with ReLU activation learn local visual patterns. Each convolutional block is followed by 2 × 2 max pooling.
- Classification: The extracted feature maps are flattened and passed to a dense ReLU layer.
- Output: Binary problems use a sigmoid output, while multiclass problems use a softmax output.
Cross-entropy is the appropriate loss for this task, and adaptive moment estimation is commonly used to train the network. The trained model can be evaluated with a confusion matrix and the corresponding binary or multiclass classification metrics.
Typical applications include handwritten character recognition, medical image classification, visual quality inspection, remote-sensing image analysis, and species or disease identification from photographs.